
c++中有许多函数,当然,程序当中也可以自己定义。为了方便大家(还有我)查找如何使用,在做题中不断积累,本文也会不断更新。
1.unique() 去重函数
假设题目中有一数组 a ,要求将 a 从大到小输出,且相同元素只输出一个即可
做法:假设大家都知道 sort 这个东西(不知道的话,就随便写个排序吧),那就先 sort 一下,使元素按一定顺序(从大到小或从小到大)排列,然后:
int length= unique(/跟sort里面几乎一样/) - 数组名;
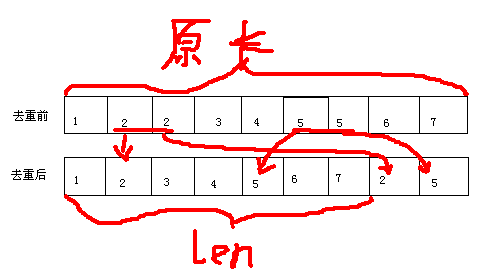
此处的 length 储存的是去重后数组的大小
unique 函数并非将相同的数字删去,而是将其移到了数组的最后面,如图:

2.sort() 快速排序
将数组的一部分进行排序 头文件:algorithm
核心代码(一般不需要记,可以直接调用):
void sort(int *a, int l, int r) {
//时间复杂度 递归式T(n) = O(n) + 2*T(n)
//即 O(nlogn)
swap(a[l], a[rand()*rand()%(r-l+1)+l]);
int tmp = a[l]; //右边的元素均小于tmp,左边的元素均大于tmp
int l_ = l, r_ = r;
while(l < r) { //循环的时间复杂度为区间长度
while(l < r) {
if(a[r] > tmp) r--; //a[r]落在正确的位置,不需要被调整
else { a[l++] = a[r]; break; }
}
while(l < r) {
if(a[l] < tmp) l++; //同上
else { a[r--] = a[l]; break; }
}
}
a[l] = tmp;
if(l-l_ > 1) sort(a, l_, l-1);
if(r-r_ > 1) sort(a, r+1, r_);
}
sort函数一般默认为从小到大排序,当需要将数组从大到小排序或要将结构体排序时,需要手写函数:
//数组从大到小排序
bool cmp1(int x, int y) {
return x > y; //从大到小排序
//return x < y; 从小到大排序
}
//结构体排序
struct node {
int w, id;
};
bool cmp2(node x, node y) {
//将结构体 x, y按照 w 从大到小排序,当 x,y 的 w 的值相等时,按照 id 从小到大拍
if(x.w == y.w) return x.id < y.id;
return x.w > y.w;
}
sort的应用:快速选择
int select(int *a, int l, int r, int k) {
swap(a[l], a[rand()*rand()%(r-l+1)+l]);
int tmp = a[l];
int l_ = l, r_ = r;
while(l < r) {
while(l < r) {
if(a[r] > tmp) r--; //a[r]落在正确的位置,不需要被调整
else { a[l++] = a[r]; break; }
}
while(l < r) {
if(a[l] < tmp) l++; //同上
else { a[r--] = a[l]; break; }
}
}
a[l] = tmp;
if(k == l-l_+1) return a[l];
if(k < l-l_+1) return select(a, l_, l-1, k); //比较tmp左边的元素
if(k > l-l_+1) return select(a, r+1, r_, k-(l-l_+1)); //比较tmp右边的元素
}
3.lower_bound() 及 upper_bound()
lower_bound(val) :返回容器中第一个值大于等于val 的元素的 iterator 位置
upper_bound(val) :返回容器中第一个值大于val 的元素的 iterator 位置
其实这两个函数是这样子用的:
int x, y;
int pos[MAXN];
for(int i = 1; i <= n; i++) scanf("%d", &pos[i]);
sort(pos+1, pos+1+n);
for(int i = 1; i <= q; i++) {
scanf("%d%d", &x, &y);
cout << upper_bound(pos+1, pos+n+1, y) - lower_bound(pos+1, pos+n+1, x) << 'n';
}
4. _gcd(a, b)
返回a,b的最大公约数,若a为0返回b,若b为0返回a,若都为0返回0。在头文件
其实这个函数也可以手写,而且并不长
int gcd(int x, int y) {
return !x ? y : gcd(y % x, x);
}
不如再说一说 lcm 吧(反正是用 gcd 求)
求出 a, b 两个数的 gcd 后,可以知:( a/gcd , b/gcd ) = 1. 即 a/gcd 与 b/gcd 互质
则 lcm = gcd * ( a/gcd ) * ( b/gcd )
即lcm = a * b / gcd
为了防止 a * b 会爆 long long , 所以我们在求 lcm 时, 一般这样:lcm = a / gcd * b
所以可以得到一个式子:a * b = gcd * lcm
5.getline()
getline() 函数是读入整行文本
其原型为:istream& getline ( istream &is , string &str , char delim );
其中 istream &is 表示一个输入流,譬如cin;string&str表示把从输入流读入的字符串存放在这个字符串中(可以自己随便命名,str什么的都可以);char delim表示遇到这个字符停止读入,在不设置的情况下系统默认该字符为'n',也就是回车换行符(遇到回车停止读入)。
例如:在 getline(cin, line, '#') 中,如果输入“you are the #best”,实际line中只有“you are the”
在输入时,Windows可以通过Ctrl+z使输入停止,Linux中,可以用Ctrl+d
6. tolower()
功能:把字符转换成小写字母,非字母字符不做出处理
头文件:
#include<iostream>
#include<string>
#include<cctype>
using namespace std;
int main() {
string str = "THIS IS A STRING";
for (int i = 0; i < str.size(); i++)
str[i] = tolower(str[i]);
cout << str;
return 0;
}
7. nth_element()
使第n大元素处于第n位置(从0开始,其位置是下标为n的元素),并且比这个元素小的元素都排在这个元素之前,比这个元素大的元素都排在这个元素之后,但不能保证他们是有序的
比较适合用来寻找中位数
使用方法:nth_element(start, start+n, end)
#include <algorithm>
#include <iostream>
#include <cstring>
#include <cstdio>
using namespace std;
const int N=101;
char s[N];
int main()
{
int len,n;
gets(s);
len=strlen(s);
scanf("%d",&n);
nth_element(s,s+n,s+len);
puts(s);
return 0;
}
待更新中。。。。
原文链接: https://www.cnblogs.com/v-vip/p/9030247.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍
原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/273860
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!