
TensorFlow [1] is an interface for expressing machine learning algorithms, and an implementation for executing such algorithms.
TensorFlow的功能:1、提供接口表达机器学习算法。2、执行这些机器学习算法。
A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-
使用TensorFlow表达的计算模型,可以在不做修改或者修改一点后再异构的系统上运行,包括移动设备(手机等)。
scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.
TensorFlow编程模型和基本概念
A TensorFlow computation is described by a directed graph, which is composed of a set of nodes. The graph represents a dataflow computation, with extensions for allowing some kinds of nodes to
一个TensorFlow计算使用一个由节点集合组成的有向图进行描述(简单说:有向张量计算流图)。有向图表达了一个数据流的计算,允许节点保持和更新状态,并且有分支和循环控制结构的功能,控制有向图的执行。客户端使用python或c++语言构造一个计算有向图。下面的例子是用python构建并且执行一个TensorFlow图的程序和执行过程图。
import tensorflow as tf
b = tf.Variable(tf.zeros([100])) # 100-d vector, init to zeroes
W = tf.Variable(tf.random_uniform([784,100],-1,1)) # 784x100 matrix w/rnd vals
x = tf.placeholder(name="x") # Placeholder for input
relu = tf.nn.relu(tf.matmul(W, x) + b) # Relu(Wx+b)
C = [...] # Cost computed as a function # of Relu
s = tf.Session()
for step in xrange(0, 10):
input = ...construct 100-D input array ... # Create 100-d vector for input
result = s.run(C, feed_dict={x: input}) # Fetch cost, feeding x=input
print step, result


In a TensorFlow graph, each node has zero or more inputs and zero or more outputs, and represents the instantiation of an operation. Values that flow along normal edges in the graph (from outputs
在TensorFlow有向图,每个节点有0个或多个输入和0个或多个输出,并且表示一个操作的实例化(真正的计算)。在图中沿着普通边流动的数据(输出和输入)都是张量。任意维度的数组,可以显式的知名或者在构建图的时候自动推断出来。
有向图中还可以有一种特殊的边,叫做控制依赖:没有数据流过这些边,作用是保证source node的操作必须在destination node执行前完成。
Since our model includes mutable state, control dependencies can be used directly by clients to enforce happens before relationships. Our implementation also sometimes inserts control dependencies
由于我们的模型包含不稳定状态,控制依赖可以被客户端直接用来在产生关系前强制发生???
我们的应用有时也会插入控制依赖,to enforce orderings between otherwise independent operations as a way of, for example, controlling the peak memory usage.
操作与核
操作代表一个抽象计算(矩阵相乘、相加)。一个操作有多个属性,必须给出属性信息或者能够在构建图的时候推断出来,以便能实例化一个节点执行操作。一个常见的属性用法是执行多态操作(将两个浮点张量相加或将两个int32类型的张量相加)
核:代表可以在特定设备(cpu/gpu)上执行的特定操作的实现。
TensorFlow的binary定义了一个可用的操作和核的集合,这个集合里面的操作和核是通过注册机制加入的。这个集合是可以通过连接额外的完成注册的操作或核,以达到扩展的目的。
会话
会话:客户端通过会话与TensorFlow系统进行交互。要创建计算有向图,会话接口支持额外的方法增加额外的节点或边,以拓展由当前会话维护的图。
The other primary operation supported by the session interface is Run, which takes a set of output names that need to be computed, as well as an optional set of tensors to be fed into the graph in
另外的由会话接口支持的主要操作是Run,输入时需要计算的输出名(product=tf.matmul(m1,m2),这里product就可以作为输入),以及一个可选的可以用来fed的张量(result = sess.run(product) result就是可选张量)。
place of certain outputs of nodes. Using the arguments to Run, the TensorFlow implementation can compute the transitive closure of all nodes that must be executed in order to compute the outputs
通过设置Run的参数,TensorFlow可以计算所有节点(必须执行以便计算所有必须的输出)的传递闭包(例如
one = tf.constant(1) new_value = tf.add(state, one) update = tf.assign(state, new_value)sess.run(update))。
这里sess.run(update)就会顺序计算(one,new_value,update)这三个张量,传递闭包
并且能安排执行适当的有相关依赖的节点
that were requested, and can then arrange to execute the appropriate nodes in an order that respects their dependencies (as described in more detail in 3.1). Most of our uses of TensorFlow set up a
大多数TensorFlow的使用者建立一个图的时候生成一个会话,通过调用Run执行全图或者子图成千上万次。
变量
在大多数计算中,图会被计算很多次。大多数张量在一个图执行完后就会失效。然而变量是一种特殊的操作,在一个图执行后,可以返回一个可变张量的句柄。这个与持续可变张量相关的句柄,可以被传递给多个特殊操作,例如Assign或AssignAdd这种改变张量的操作。对于一个基于TensorFlow的机器学习应用,模型的参数被存储在张量中,并且作为模型训练图的一部分随着模型的执行而更新。
待续20161220
3 TensorFlow实现
TensorFlow系统的主要部分是客户端,客户端使用会话接口与master交互,与一个或多个worker进程通信,每个worker进程在master的指导下,负责决定使用哪个设备(cpu核/gpu卡)执行计算。TensorFlow接口有两种实现方式:local(本地)和distributed(分布式)。
本地模式:客户端、master、worker都运行在单一机器上(可能有多个计算设备(cpu/gpu))。
分布式模式:共享所有的本地实现的代码。但是对本地代码拓展以支持在不同机器上运行在不同进程的客户端,master,workers。在分布式环境下,这些不同的任务由集群调度系统进行管理。这两种模型的不同请见下图。
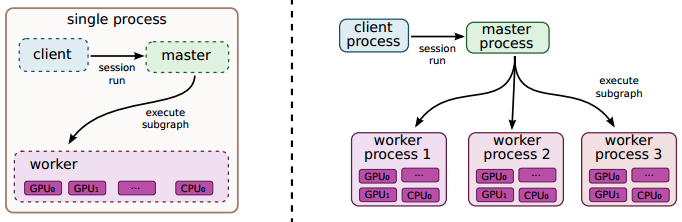
设备
Devices are the computational heart of TensorFlow. Each
设备是TensorFlow进行计算的“心脏”。每个worker主管一个或多个设备,并且每个设备有一个设备类型和名称。设备名称是由设备类型、在worker机器中设备索引、job和task序数
举个例子,设备名称如下 "/job:localhost/device:cpu:0" 或者"/job:worker/task:17/device:gpu:3"。TensorFlow已经为cpu和gpu实现了大量接口,并且新的设备可以通过注册机制加入TensorFlow中。每个设备对象负责管理分配或回收设备内存。
张量
在我们的应用中一个张量是有类型的多维数组。我们支持多种张量元素类型,包括signed、unsigned整型数从8位到64位。ieee float类型,双精度类型、复杂数字类型、字符串类型。合适大小的后台存储通过一个分配器进行管理,该分配器由张量所处的设备确定。张量的后端存储缓存是引用计数的并在没有引用存在时解除分配。
3.1单一设备执行
首先考虑最简单的执行场景:一个worker进程拥有一个设备。图中的节点按顺序执行,并且考虑节点间的依赖关系
特殊的,我们跟踪还没有执行的节点的计数器,这个计数器记录了每个没有执行的节点的依赖关系个数。一旦计数器变成0,节点就会变成适合执行,这时就会被加入到就绪队列(ready queue)
就绪队列会不按指定顺序执行,对节点授权在设备对象上对核执行。当一个节点结束执行,所有依赖于完成计算节点的“依赖计数器”都会减1.
3.2 多设备执行
如果系统有多个设备,这时会有两个负责的问题要解决:决定图中的每个节点在哪个设备上计算;管理设备间数据传输的请求;
3.2.1 节点安排
给定一个计算有向图,TensorFlow应用一个主要的职责就是将计算映射到可用的设备集合。这里先介绍这个映射算法的简单版本,可以在4.3节看到算法的拓展版本。节点分配算法的输入参数之一:cost model(代价模型)
代价模型包含对每个图节点中输入和输出张量的大小的估计,移机每个节点对输入张量进行计算时间的估计。代价模型可以是基于因不同类型操作的静态估计,或者是使用已经执行的图中实际的节点安排决策进行估计
原文链接: https://www.cnblogs.com/wangq17/p/6203516.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/246204
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!