
VRIP(Volumetric Range Image Processing),顾名思义,是从深度图重建网格的一种方法。VRIP是Brian Curless和Marc Levoy在1996年提出来的方法,距今已经有20年的历史了,依然属于最好的方法之一。
VRIP的核心问题是
已知世界坐标系下,某物体表面(f)在不同视角下的深度图(hat{f_1},...,hat{f_K}),求(f)。这里隐含深度图在世界坐标系下的位姿是已知的。
许多三维测量方法,比如激光、TOF、结构光、双目视觉等,都可以得到深度图。因此这是一个非常有意义的问题。如何将这些深度图融合成为一个平滑的单一网格呢?这就是VRIP要解决的问题。
下面给出一个结构光成像的例子。左上图是将不同视角拍摄到的深度图(已转化为三维网格)匹配在一起后的情形。右上图是左图中某一部分的切面,可以看到很多层网格重叠在一起,噪声、匹配误差、采样率等都反映在这个局部中。左下图是VRIP的结果,右下图是VRIP融合的结果和深度图放在一起(棕色是深度图,蓝色是融合后的网格,只能看到一点点)。
VRIP的基本假设
VRIP最重要的假设是测量误差沿着光线传播方向(投影方向)并服从高斯分布。假设(hat{f_k}(u,v))是在第(k)个视角下,光线从传感器((u,v))位置沿着传播方向到达(f)的距离的测量值,(f_{k}(u,v))为其真实值。那么条件概率满足
(P(f_{k}(u,v)|hat{f_k}(u,v))=c_k(u,v)exp[-frac{1}{2}(frac{hat{f_k}(u,v)-f_k(u,v)}{sigma_k(u,v)})^2])
因此,VRIP算法和视角非常相关。
VRIP的模型
VRIP尝试从概率的角度来描述核心问题。对任意曲面(f),(P(f|hat{f_1},...,hat{f_K}))为(f)的条件概率。那么求解核心问题转化为一个最大似然问题
(max_{f}P(f|hat{f_1},...,hat{f_K}))
经过一系列独立性假设,
(P(f|hat{f_1},...,hat{f_K})= prod_{k=1}^{K}prod_{i=1}^{M}prod_{j=1}^{N}P(f_{k}(i,j)|hat{f_k}(i,j)))
取对数,并转化为求和
(E(f)=-SigmaSigmaSigma log[P(f_{k}(i,j)|hat{f_k}(i,j))])
将离散情形转换为连续情形
(E(f)=-Sigmaintint_{A_k}log[P(f_{k}(u,v)|hat{f_k}(u,v))]dudv)
定义(d(u,v,f_k)=hat{f_k}(u,v)-f_k(u,v)),代入(P)的表达式,则有
(E(f)=frac{1}{2}Sigmaintint_{A_k}w_k(u,v)d_k(u,v,f_k)^2 du dv)
上式还是建立在各个视角下的局部坐标系(传感器坐标系)。将上式转换到世界坐标系下,有
(E(f)=frac{1}{2}Sigmaintint_{A}w_k(x,y,z)d_k(x,y,z)^2[mathbf{v_k}(x,y,z)cdot (frac{partial z}{partial x}) ,frac{partial z}{partial y},-1)] dx dy)
其中(z=f(x,y)) ,(mathbf{v_k})是第(k)个视角的投影方向,(d_k(x,y,z)=hat{f}(x,y,z,mathbf{v_k})-f(x,y)) ,为三维点((x,y,z))沿着第(k)个视角的投影方向与深度图对应点的测量值(hat{f})的距离,即Signed Distance Function。积分中点乘那项是从(uv)坐标系转换到(xyz)坐标系的(Jacobian)矩阵。
下图是SDF的示意图。注意靠近传感器的方向距离为正,远离传感器的方向距离为负。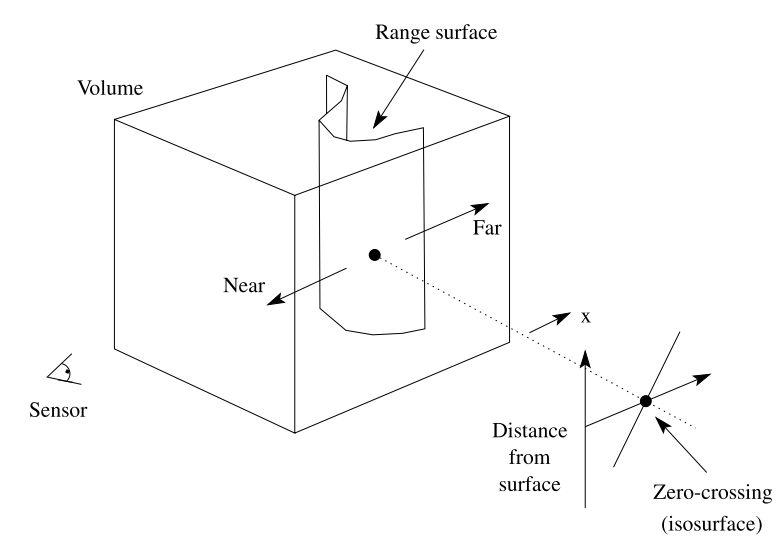

下图是同一个三维点在两个视角下的SDF示意图。注意SDF是沿着视角方向(光线传播反方向)的。图中(d_1<0,d_2>0)。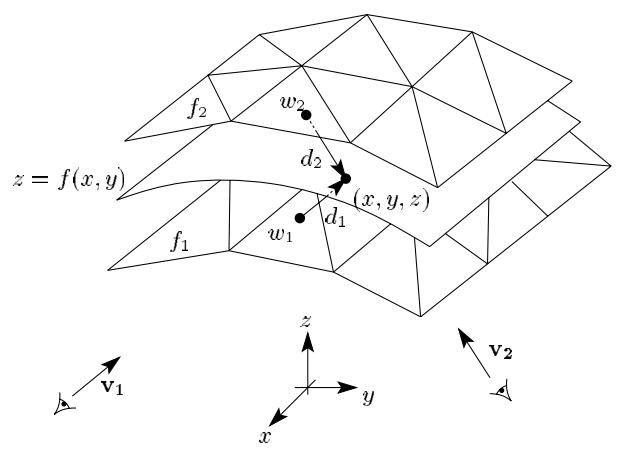
于是,问题转换为
求(,使得z=f(x,y),使得)(E(f))最小。
求解这个问题涉及到很多偏导数、方向导数的知识,本人也并没有完全搞明白。但问题的解却是出乎意料的简单
若(z=f(x,y))满足(Sigma w_k(x,y,z)d_k(x,y,z)=0) ,则(z)是最优解。
VRIP算法流程
定义(D(mathbf{x})=frac{Sigma w_k(mathbf{x})d_k(mathbf{x})}{Sigma w_k(mathbf{x})}),那么(D(mathbf{x})=0)就是我们要重构的三维表面。实际应用中,(D(mathbf{x}))可看作一个三维体数据(volume),(D(mathbf{x})=0)通过提取(D)的零等值面即可得到。因此,算法先增量构建(D),然后通过等值面提取方法得到三维网格。例如,Marching Cube就是一种高效提取等值面的算法,而且非常适合在GPU上实现。
需要指出的是,作者在论文中采用了TSDF(Truncated signed distance function),即在一条光线上,只考虑测量值(hat{z})附近一定范围(hat{z}pm delta z)内的体素。一方面是因为一条光线可能会穿过物体不止一次。另一方面这样也可以减小搜索范围,加速算法。
VRIP算法的框架如下:
/* 初始化 */
对每个三维体素,设其权重为0。
/* 深度图融合 */
对每个深度图 {
/* 准备 */
网格化深度图;
计算每个点的权重;
/* 更新体素 */
对该视角下FOV中的体素 {
沿投影方向找到深度网格中的对应点;
计算其沿投影方向的SDF;
插值得到其权重;
更新这个体素的权重和SDF。
}
}
/* 表面提取 */
提取零等值面。
着重强调一点,深度图的权重需要尽量准确,特别是(1)对噪声大的点能够赋予较小的权重,(2)对于法向量和视角方向角度比较大的三维点,可以降低其权重(曲率大,采样率不够,重建误差大)。
下图是两个视角下的TSDF的融合的示意图。
下图是多个视角下TSDF的融合(两颗真实的牙齿)
VRIP的优缺点
VRIP的优点主要有
- 它是一定意义下的最大似然解。这保证了解的精度。
- 它是一个增量方法,每一次得到新的深度图后,可简单快速地加入到TSDF中。
- 适合并行处理,可用GPU加速
VRIP的主要缺点有
- VRIP生成的网格会附加一定的平滑效果,在存在噪声和匹配误差的情况下有时不能重建出细微的结构。
- 如果深度图存在匹配误差,VRIP并不能消除这些误差。这些误差会反映在融合后的网格中(分层、噪声等)。
VRIP的加速
VRIP算法的时间复杂度比较高。作者在CPU端做了很多优化和加速工作。假设深度图平行于(xy)平面,且投影方向为正交投影,那么沿(z)方向的所有体素在深度图上的投影相同,因此其TSDF可以在(z)方向上简单计算得到,而且权重相等,不必要重复运算。作者的主要思路是,将不同视角下的深度图和坐标系,通过仿射变换和重采样,映射到相对标准的位置(深度图平行于(xy)平面),从而减少投影和权重的计算量。
如下图所示,(a)某个视角下的深度图及正交投影方向,投影方向和Voxel slices有一个夹角。(b)通过一个仿射变换,将投影方向变换为与Voxel slices相垂直。一般而言,仿射变换后深度图和Voxel slices仍然有夹角,因此还要将它在平行于slices的平面上重采样。(c)将计算得到的TSDF变换回原坐标系下的距离。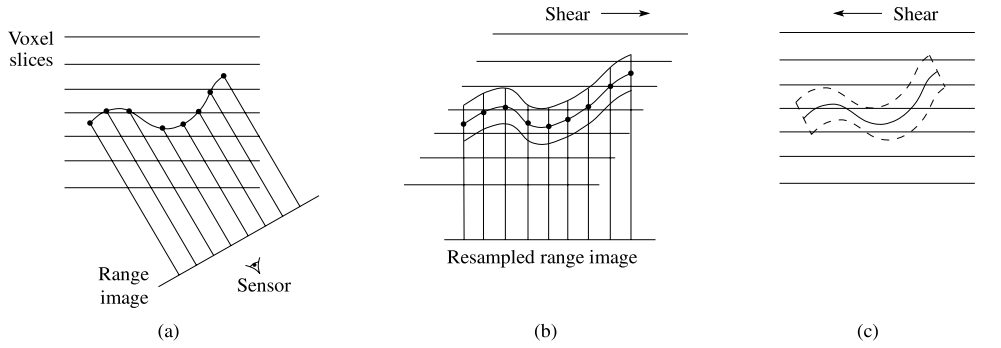
VRIP在SLAM中的应用
VRIP算法在RGBD SLAM中有着广泛的应用。Kinect Fusion的作者并没有采用CPU加速的方法,而是将VRIP算法移植到GPU上,利用Ray casing算法做到了网格的实时显示,效果非常好。后来的Kintinuous、Elastic Fusion、Dynamic Fusion也都采用类似的架构去生成网格。
原文链接: https://www.cnblogs.com/luyb/p/5658784.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/236756
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!