
本工具从最初版的跳转分布图只为了更直观地分析反汇编代码的分支结构,第三版开始对直观图进行逆向分支代码的输出,第四版对分支输出策略的一些探索,第五版结合之前的探索进行改进。第六版在现在功能的基础上进行增强,利用第六版(一)的基本功能-直译,第六版(二)对条件分支增加条件判断翻译,以及改进在函数调用处附带备选参数参考。
第六版(四),在(三)的基础上增加对原子操作指令的逆向以及c++函数的逆向。
本篇是(五),对待c风格的函数符号调用的翻译,通过导入c风格符号的函数原型来参考分析。
上一篇在介绍对待 c++风格的函数符号调用的情况,提到了c风格的函数符号没有太多的原型信息可供参考,但是它唯一不被重载,参数约定使用标准的约定,所以用古老(老土)的办法就好了。就是导入c风格符号的函数原型(主要是符号名和参数序列)。
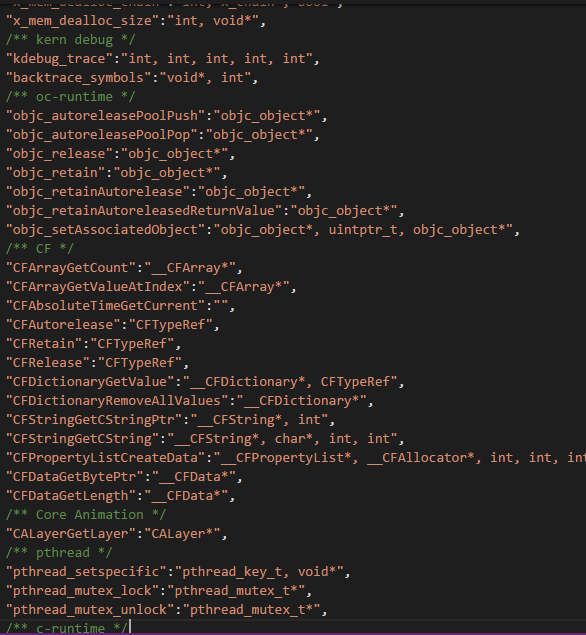

有外部的是参考信息,就可以对函数调用配用相应的寄存器和存储单元。我并不想让机器去试图臆意猜测一个不知道原型的函数参数序列,因为过犹不及,而且不严谨,机器猜测误导坑更加大。试想一下,一个c风格的函数,你可以单从函数被调用前的准备参数的工作流就能分辨出是foo(double, int)还是foo(int, double)吗?我是不能做到这种超人的程序了,我必须要通过外部信息来指导机器进行分析工作。
下面贴上机器逆向出来的代码:
CA::Transaction::add_root
{
// 0 pushq %rbp
// 1 rbp = rsp;
// 4 pushq %r14
// 6 pushq %rbx
// 7 rbx = rsi;
// 10 r14 = rdi;
// 13 rdi = & CA::Transaction::roots_lock;
// 20 call
OSSpinLockLock(CA::Transaction::roots_lock);
// 25 rdi = CA::Transaction::roots;
// 32 testq %rdi, %rdi
// 35
if (!) { // 32 (0 != rdi)
// 37 edi = 0;
// 39 esi = 0;
// 41 edx = 0;
// 43 ecx = 0;
// 45 r8d = 0;
// 48 r9d = 0;
// 51 call
x_hash_table_new_(0, 0, 0, 0, 0, 0);
// 56 rdi = rax;
// 59 CA::Transaction::roots = rdi;
} // 66
// 66 rsi = rbx;
// 69 rdx = rbx;
// 72 call
x_hash_table_insert((x_hash_table*)rax, (uintptr_t)esi, (uintptr_t)edx);
// 77 testb %al, %al
// 79
if (!) { // 77 (0 == al)
// 81 lock
// 82 OSAtomicIncrement32((volatile int32_t*)&rbx->_0);
// 84 testb $0x10, 0x84(%r14)
// 92
if (!) { // 84 (0 == (0x10 & r14->_84))
// 94 rax = (int64_t)(int32_t&)r14->_8;
// 98 testq %rax, %rax
// 101
if () { // 98 (0 > rax)
// gen jmp 113
goto _f113;
// 103 cmpl $0x0, 0xa8(%rbx,%rax,4)
} // 111
else if () { // 103 ((int32_t&)((uint32_t*)&rbx->_a8)[rax] != 0x0)
// gen jmp 124
goto _f124;
}
else { // 111 next
_f113: // from 101
} // 113
// 113 rdi = rbx;
// 116 rsi = r14;
// 119 call
((CA::Layer*)rbx)->thread_flags_((CA::Transaction*)r14);
_f124: // from 111
} // 124
} // 124
// 124 rdi = & CA::Transaction::roots_lock;
// 131 popq %rbx
// 132 popq %r14
// 134 popq %rbp
// 135 ret
return; // jmp 0x1041ecb2a; symbol stub for: OSSpinLockUnlock
// 140 rbx = rax;
// 143 rdi = & CA::Transaction::roots_lock;
// 150 call
OSSpinLockUnlock(CA::Transaction::roots_lock);
// 155 rdi = rbx;
// 158 call
_Unwind_Resume;
// 163 nop
/*****
* global variables
*
*/
// 13 extern ent_off__0x5146c; leaq 0x51458(%rip), %rdi; CA::Transaction::roots_lock
// 25 extern ent_off__0x51464; movq 0x51444(%rip), %rdi; CA::Transaction::roots
// 59 extern ent_off__0x51464; movq %rdi, 0x51422(%rip); CA::Transaction::roots
// 124 extern ent_off__0x5146c; leaq 0x513e9(%rip), %rdi; CA::Transaction::roots_lock
// 143 extern ent_off__0x5146c; leaq 0x513d6(%rip), %rdi; CA::Transaction::roots_lock
}
CA::Transaction::add_root
CA::Transaction::run_deferred_visibility_layer_calls
{
// 0 pushq %rbp
// 1 rbp = rsp;
// 4 pushq %r15
// 6 pushq %r14
// 8 pushq %rbx
// 9 pushq %rax
// 10 r14 = rdi;
// 13 rbx = r14->_78;
// 17 testq %rbx, %rbx
// 20
if (!) { // 17 (0 == rbx)
_b22: // from 81
// 22 r15 = rbx->_0;
// 25 testq %r15, %r15
// 28
if (!) { // 25 (0 == r15)
// 30 rdi = r15;
// 33 call
((CA::Layer*)r15)->call_did_become_visible();
// 38 eax = 0xffffffff;
// 43 lock
// 44 OSAtomicAdd32(eax, (volatile int32_t*)&r15->_0);
// 48 cmpl $0x1, %eax
// 51
if (!) { // 48 (eax != 0x1)
// 53 rdi = r15;
// 56 call
((CA::Layer*)r15)->~Layer();
// 61 edi = 0xb;
// 66 rsi = r15;
// 69 call
x_mem_dealloc_bucket(0xb, (void*)r15);
} // 74
} // 74
// 74 rbx = rbx->_8;
// 78 testq %rbx, %rbx
// 81
if () // 78 (0 != rbx)
goto _b22;
// 83 rdi = r14->_78;
// 87 call
x_list_free((x_list*)r14->_78);
// 92 r14->_78 = 0x0;
} // 100
// 100 rsp = rsp + 0x8;
// 104 popq %rbx
// 105 popq %r14
// 107 popq %r15
// 109 popq %rbp
// 110 ret
return;
// 111 nop
}
CA::Transaction::run_deferred_visibility_layer_calls
原文链接: https://www.cnblogs.com/bbqzsl/p/5512642.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍
原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/233673
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!