
引言
上一节我们把向量和矩阵的类写好了,接下来我们进入到实战环节——搭建框架。因为光栅化拥有一套非常规范的渲染管线,我们的目的就是要还原它最重要的部分。当然在此之前,我们也要把画布先配置好。
画布配置
之所以选择Qt来制作软渲染器,是因为Qt能创建带窗体的工程,其中窗体上面拥有一张可以绘制像素的画布(canvas)。但是相应的,其工程架构也较为复杂,因此我们首先要剖析一下Qt的工程结构:

刚创建工程的时候,项目文件夹里应该只有画框的这4个文件。其中main.cpp是运行工程的主体文件,工程在start running时会直接跑main.cpp中的main()函数;mainwindow是一个窗体类,里面包括了打开窗体以后的所有逻辑;由于窗体需要展示一个可视化界面,因此还外置了一个mainwindow.ui作为界面的配置文件(和传统前端差不多,这种前端也有html语言和极其类似css的qss层叠样式表)。这里我们着重看一下mainwindow的类:
1 #ifndef MAINWINDOW_H
2 #define MAINWINDOW_H
3
4 #include <qmainwindow>
5 QT_BEGIN_NAMESPACE
6 namespace Ui { class MainWindow; }
7 QT_END_NAMESPACE
8
9 class MainWindow : public QMainWindow
10 {
11 Q_OBJECT
12
13 public:
14 MainWindow(QWidget *parent = nullptr);
15 ~MainWindow();
16
17 private:
18 Ui::MainWindow *ui;
19 };
20 #endif // MAINWINDOW_H
首先要知道的是,我们的窗体类其实是继承了一个窗体模板:QMainWindow,我们是想在拥有窗体的基础上添加或修改一些内容;下面系统定义了一个ui指针,它指向的就是mainwindow.ui的内容。
上面这两条信息知不知道都无所谓,还是来讲讲绘制操作相关的内容吧。首先,Qt自带一个update()函数,它是用来刷新或更新帧的,每当update()被调用后,都会自动调用paintevent(QPaintEvent *event)函数,而这个函数就是用来重绘画布的。现在我们要定义自己的绘制方法,只需要重写一下paintevent函数就可以了。
查看paintevent函数的源码后会发现它是一个虚函数。回忆第一节我们讲的内容,对于基类的虚函数,我们要在派生类中重写它:
void paintEvent(QPaintEvent *) override;
接下来我们需要在.h中声明一个QImage类型的指针变量canvas作为绘制对象,然后在.cpp中重写paintEvent,具体思路就是先创建一个笔刷painter,然后用painter将canvas绘制到窗体中:
1 void MainWindow::paintEvent(QPaintEvent *event)
2 {
3 if(canvas)
4 {
5 QPainter painter(this);
6 painter.drawImage(0,0,*canvas); //表示在窗体的(0,0)坐标开始绘制
7 }
8 QWidget::paintEvent(event);
9 }
画布就配置好了。不过大家也意识到canvas从头到尾就是个野指针,所以现在跑工程肯定是会崩的。要想让Qt的painter成功将canvas贴到窗体上,我们就必须向canvas里写入内容。通过查看api接口,发现QImage的构造函数是:
QImage(uchar *data, int width, int height, Format format, QImageCleanupFunction cleanupFunction = Q_NULLPTR, void *cleanupInfo = Q_NULLPTR);
其中只有前4项是我们需要关注的,分别是颜色数据指针、画布宽度、画布高度、颜色类型。画布宽度和画布高度直接获取窗体的宽高就可以了,颜色类型我们默认都使用QImage::Format_RGBA8888(真彩24色位图),这个颜色数据指针怎么理解呢,它是一个unsigned char类型的一维数组指针,这个一维数组存储了整张图中每一个像素的rgba通道信息。要注意的是,r、g、b是分着存的,比如[0]是坐标(0,0)像素的r通道值,[1]是坐标(0,0)像素的g通道值,[4]是坐标(0,1)像素的r通道值,以此类推。因此我们需要在mainwindow.h里再声明一个unsigned char类型的指针*data,canvas由以下语句来完成赋值:
canvas = new QImage(data, width(), height(), QImage::Format_RGBA8888);
但是我们现在还不知道谁来提供颜色数据,只有接下来引入并完成“帧缓冲”这个步骤,我们才能解答这个问题。
帧缓冲
图形学中,帧缓冲是一个很重要的概念。我们在将像素写入图样时,不可能每更新一个像素就刷新一次屏幕,最合理的方法是当画布中所有像素都被写入以后再刷新屏幕。如果想要这样,我们就必须创建一个用于存储所有像素点的颜色信息的缓冲区,这里我们把它称作帧缓冲(framebuffer)。现在我们需要创建这个类:
1 #ifndef FRAMEBUFFER_H
2 #define FRAMEBUFFER_H
3 #include "vector4d.h"
4
5 class FrameBuffer
6 {
7 private:
8 int width,height;
9 unsigned char mp[8294405];
10 public:
11 FrameBuffer(int w,int h):width(w),height(h){}
12 ~FrameBuffer(){}
13 void Fill(Vector4D vec);
14 void Cover(int x,int y,Vector4D vec);
15 unsigned char *getColorBuffer();
16 };
17
18 #endif // FRAMEBUFFER_H
帧缓冲类首先包括窗体的宽高,不多赘述;还要包括上文提到的颜色数据数组mp,它对应的就是mainwindow中更新canvas用的像素数据data。由于目前电脑屏幕常用最大分辨率为19201080,每个像素需要有4个通道信息,因此数据数组的大小至少为19201080*4=8294400。
接下来看一下成员函数,构造函数和析构函数没什么内容直接跳过;这里先定义了一个Fill()函数,作用是对画布中的所有像素进行初始化,传入参数就是初始化颜色;Cover()就是用来更新(x,y)坐标颜色的函数。然后又由于mp是private类型的,要想获取mp地址,需要再写一个getColorBuffer函数来获取像素数据的地址(或指针)。
.cpp文件:
1 #include "framebuffer.h"
2
3 void FrameBuffer::Fill(Vector4D vec){
4 unsigned char cl[4];
5 cl[0]=static_cast<unsigned char>(vec.x*255);
6 cl[1]=static_cast<unsigned char>(vec.y*255);
7 cl[2]=static_cast<unsigned char>(vec.z*255);
8 cl[3]=static_cast<unsigned char>(vec.w*255);
9 for(int i=0;i<height;i++){
10 for(int j=0;j<width;j++){
11 for(int k=0;k<4;k++){
12 mp[(i*width+j)*4+k]=cl[k];
13 }
14 }
15 }
16 }
17 void FrameBuffer::Cover(int x,int y,Vector4D vec){
18 unsigned char cl[4];
19 cl[0]=static_cast<unsigned char>(vec.x*255);
20 cl[1]=static_cast<unsigned char>(vec.y*255);
21 cl[2]=static_cast<unsigned char>(vec.z*255);
22 cl[3]=static_cast<unsigned char>(vec.w*255);
23 for(int k=0;k<4;k++){
24 mp[(y*width+x)*4+k]=cl[k];
25 }
26 }
27 unsigned char* FrameBuffer::getColorBuffer(){
28 return mp;
29 }
要注意的是,传入的vec向量的rgb值范围是[0,1],表示的是一个比率,而最后写入到数据里需要映射到[0,255],这是因为我们提前设置了颜色数据类型为RGBA_8888。至此,我们帧缓冲的部分就介绍完毕了。
接下来,我们就可以回答上面的遗留问题了:颜色数据的来源就是FrameBuffer,我们接下来各种对像素的计算和赋值,最后都要写入到FrameBuffer做缓冲。当画布已经被装填满了时,我们再对canvas进行填充。这一步具体的实现方法我会放在后几章讲。
最后放一下mainwindow类的代码:
.h:
1 #ifndef MAINWINDOW_H
2 #define MAINWINDOW_H
3
4 #include <QMainWindow>
5
6 QT_BEGIN_NAMESPACE
7 namespace Ui { class MainWindow; }
8 QT_END_NAMESPACE
9
10 class MainWindow : public QMainWindow
11 {
12 Q_OBJECT
13
14 public:
15 MainWindow(QWidget *parent = nullptr);
16 ~MainWindow();
17
18 private:
19 void paintEvent(QPaintEvent *) override;
20
21 private:
22 Ui::MainWindow *ui;
23 QImage *canvas;
24 };
25 #endif // MAINWINDOW_H
.cpp:
1 #include "mainwindow.h"
2 #include "ui_mainwindow.h"
3 #include "QPainter"
4
5 void MainWindow::paintEvent(QPaintEvent *event)
6 {
7 if(canvas)
8 {
9 QPainter painter(this);
10 painter.drawImage(0,0,*canvas);
11 }
12 QWidget::paintEvent(event);
13 }
接下来我会讲述图形学的一大核心部分——渲染管线篇。这一部分非常重要,它是图形学中渲染部分的骨架,支撑着所有渲染相关的操作实现。渲染管线相关的知识我在另一篇博客中详述过,这里就不再复述了。要想摸透渲染器的运行原理,理解渲染管线是第一步。
考虑到软渲染器的效率及工程量,我们肯定不会去复现unity内置的复杂渲染管线,这里只提取至关重要的两大步骤——着色器、光栅化。还记得管线最开始处理的对象是什么吗?没错,是顶点。我们至今都没有定义顶点,因此第一步,我们需要创建一个polygon(多边形)类,来记录顶点类和网格体类。
几何单元
首先创建最基础的几何单位——顶点。
注意,顶点可不是记录一个位置就完事了,有unity-shader基础的同学可以想一下在hlsl或cg语言中,我们会制作一个a2v结构体来输入顶点参数,其中包括了4、5个顶点属性(没有shader基础的同学也不用慌,只要知道一个顶点包括很多属性就ok了),其中包括位置、颜色、纹理、法线等,因此我们可以作如下定义:
1 class Vertex
2 {
3 public:
4 Vector4D position;
5 Vector4D color;
6 Vector2D texcoord;
7 Vector3D normal;
8
9 Vertex(){}
10 ~Vertex(){}
11 Vertex(Vector4D pos,Vector4D col,Vector2D tex,Vector3D nor):
12 position(pos),color(col),texcoord(tex),normal(nor){}
13 Vertex(const Vertex &ver):
14 position(ver.position),
15 color(ver.color),
16 texcoord(ver.texcoord),
17 normal(ver.normal){}
18 };
顶点的变换一般由着色器来操控,因此Vertex类里不需要写除了构造函数以外的任何方法。
创建完顶点之后,我们回想一下渲染管线的流程:顶点着色器会对顶点坐标进行变换,对法线进行变换,涉及到光照系统时还会改变顶点的基础颜色……因此当顶点被顶点着色器加工后,它将会成为一个新的顶点类型,交付给后面的片元着色器。为了形象描述这个vertex to fragment的过程,我们直接把这个加工后的顶点类型起名为V2F(vertex to fragment的谐音)。
1 class V2F
2 {
3 public:
4 Vector4D posM2W;
5 Vector4D posV2P;
6 Vector2D texcoord;
7 Vector3D normal;
8 Vector4D color;
9 double oneDivZ;
10
11 V2F(){}
12 V2F(Vector4D pMW, Vector4D pVP, Vector2D tex,Vector3D nor, Vector4D col, double oZ):
13 posM2W(pMW),posV2P(pVP),texcoord(tex),normal(nor),color(col),oneDivZ(oZ) {}
14 V2F(const V2F& ver):
15 posM2W(ver.posM2W),
16 posV2P(ver.posV2P),
17 texcoord(ver.texcoord),
18 normal(ver.normal),
19 color(ver.color),
20 oneDivZ(ver.oneDivZ){}
21 };
posM2W指的是Model to World,表示的是从模型空间变换来的世界坐标,之所以要声明世界空间坐标是因为在顶点着色器中,我们很多属性需要在世界空间中进行变换,使用世界坐标的频率会比较高;posV2P指的是View to Projection,表示的是从观察空间变换来的投影坐标,在2D渲染器中我们不涉及投影的概念,因此posV2P在这里表示的就是点的屏幕坐标。(写作posV2P纯粹是为了之后做3D更方便)
这里还涉及到了一个oneDivZ,表示的是深度测试的指标,2D渲染器照样用不上。(这部分是从其他大佬的博客中抄过来的)
空有顶点肯定是不够的,我们还要对模型整体进行分析。我们知道,无论是什么模型,它的基本几何单元都是三角形,即任何一个网格体模型mesh都是由很多三角形组成的。那么,我们既要描述模型包含哪些顶点,又要描述哪些顶点构成了哪个三角形。这一步,我们可以设置一种网格索引顺序来描述它的三角形构成。这部分是opengl中涉及到的一个基础,我直接上图:

解释一下,其实就是规定了一种三角形顶点的遍历顺序,在这种顺序下,相邻的三个顶点表示一个三角形。如上图,索引顺序其实就是[0,4,1,5,2,6...],所以041构成三角形,紧邻着415构成三角形,152构成三角形……当然也有特例,比如3、7、11三者构成的是一条直线,最后不会当成三角形进行渲染。
那么mesh的定义方法就很显而易见了:
1 class Mesh
2 {
3 public:
4 std::vector<vertex> vertices;
5 std::vector<unsigned int=""> index;
6
7 Mesh(){}
8 ~Mesh(){}
9
10 Mesh(const Mesh& msh):vertices(msh.vertices),index(msh.index){}
11 Mesh& operator=(const Mesh& msh);
12 void setVertices(Vertex* v, int count);
13 void setIndex(int* i, int count);
14
15 void triangle(Vector3D &v1,Vector3D &v2,Vector3D &v3);
16 };
vertices就是模型的顶点动态数组,下标就是对应顶点的编号;而index则存储的是索引顺序。这里我们一般不在构造函数中进行初始化,而是通过setXXX来动态初始化mesh的参数。最后哪个triangle是定义一个最简单的网格体——简单三角形,对应的方法如下:
1 #include "polygon.h"
2
3 Mesh& Mesh::operator=(const Mesh& msh)
4 {
5 vertices=msh.vertices;
6 index=msh.index;
7 return *this;
8 }
9
10 void Mesh::setVertices(Vertex* v, int count)
11 {
12 vertices.resize(static_cast<unsigned long="">(count));
13 new(&vertices[0])std::vector<vertex>(v,v+count);
14 }
15
16 void Mesh::setIndex(int* i, int count)
17 {
18 index.resize(static_cast<unsigned long="">(count));
19 new(&index)std::vector<unsigned int="">(i,i+count);
20 }
21
22 void Mesh::triangle(Vector3D &v1, Vector3D &v2, Vector3D &v3)
23 {
24 vertices.resize(3);
25 index.resize(3);
26 vertices[0].position=v1;
27 vertices[0].normal=Vector3D(0.f,0.f,1.f);
28 vertices[0].color=Vector4D(1.f,0.f,0.f,1.f);
29 vertices[0].texcoord=Vector2D(0.f,0.f);
30 vertices[1].position=v2;
31 vertices[1].normal=Vector3D(0.f,0.f,1.f);
32 vertices[1].color=Vector4D(0.f,1.f,0.f,1.f);
33 vertices[1].texcoord=Vector2D(1.f,0.f);
34 vertices[2].position=v3;
35 vertices[2].normal=Vector3D(0.f,0.f,1.f);
36 vertices[2].color=Vector4D(0.f,0.f,1.f,1.f);
37 vertices[2].texcoord=Vector2D(0.5f,1.f);
38 index[0]=0;
39 index[1]=1;
40 index[2]=2;
41 }
构造三角形这部分想多提一嘴,我们知道在渲染管线中,会先后进行三角形设置、三角形遍历、片元着色器,这个片元着色器在填充像素的时候会对三个顶点做插值,只有三个顶点的参数不同,才能制作出漂亮的渐变片元。这里亦然,为了体现后期的插值效果,我们尽可能地将三个顶点的color和texcoord赋予不同的数值。
渲染管线一共有三要素:被加工体、加工体和加工操作,到现在被加工体——几何单元已经制作完成了,接下来我们开始制作加工体——着色器。
着色器
只要你是个CGer,着色器这个玩意应该就像亲爹一样,又亲切又得供起来(x)。着色器就是管线中的工人,对于拿到的图元进行各种各样的计算和变换。每个管线所包含的着色器都不太一样,除了必须包括的顶点着色器、片元着色器以外,unity自带表面着色器,有些引擎还会包含曲面细分着色器、几何着色器,因此我们可以设置一个虚基类shader来作为所有着色器的模板,定义如下:
1 #ifndef SHADER_H
2 #define SHADER_H
3 #include "polygon.h"
4
5 class Shader
6 {
7 public:
8 Shader(){}
9 virtual ~Shader(){}
10 virtual V2F vertexShader(const Vertex &in)=0;
11 virtual Vector4D fragmentShader(const V2F &in)=0;
12 };
13
14 #endif // SHADER_H
由于VS和FS是最基础的着色器,所以虚基类里面只定义了这两个方法。注意别忘了在析构函数前面加virtual。
虚shader定义完了以后,我们就该定义第一个实shader了,这里我们起名为BasicShader,即2D渲染器种使用的最简单的着色器。.h部分就不写了,继承一下Shader就可以了。
.cpp:
1 #include "basicshader.h"
2
3 V2F BasicShader::vertexShader(const Vertex &in){
4 V2F ret;
5 ret.posM2W=in.position;
6 ret.posV2P=in.position;
7 ret.color=in.color;
8 ret.normal=in.normal;
9 ret.oneDivZ=1.0;
10 ret.texcoord = in.texcoord;
11 return ret;
12 }
13 Vector4D BasicShader::fragmentShader(const V2F &in){
14 Vector4D retColor;
15 retColor = in.color;
16 return retColor;
17 }
你可能想说,这着色器里面的内容也太简单了,合着啥变换都没有。没错,2D渲染器就这么简单,但出于对渲染管线的“尊重”,我们还是要把流程写全,这也是为后期做3D打基础。
截至目前,加工者也制作完成了。顶点、网格体和着色器都已经准备好了后,我们就可以“开工”了!
渲染循环附件
这里可能是整个2D渲染器系列最难分析的一步,毕竟核心往往都是最难的。作为串联一切渲染操作的管线,我们必须先明确它要拥有哪些数据和资源。
首先,作为掌控全局的管线,必定承担起分析、计算、产生颜色,并将颜色送向帧缓冲的责任,那么它必须拥有一个缓冲区的指针,且必须知道当前画布的长与宽;此外,渲染管线需要拿到所有的模型数据以及三角形顶点索引,才能进行整体分析;最后渲染管线必须知道自己使用的是哪一套着色器。
除此之外,我们还有一些设置可以进行选择,例如光照模式ShadingMode(在光照的博客中会详解)、光栅化模式RenderMode(对三角形进行描线还是填充)。
别着急开写,这里我想引入一个概念——双缓冲。
它的描述是这样的:“在图形图像显示过程中,计算机从显示缓冲区取数据然后显示,很多图形的操作都很复杂需要大量的计算,很难访问一次显示缓冲区就能写入待显示的完整图形数据,通常需要多次访问显示缓冲区,每次访问时写入最新计算的图形数据。而这样造成的后果是一个需要复杂计算的图形,你看到的效果可能是一部分一部分地显示出来的,造成很大的闪烁不连贯。 而使用双缓冲,可以使你先将计算的中间结果存放在另一个缓冲区中,但全部的计算结束,该缓冲区已经存储了完整的图形之后,再将该缓冲区的图形数据一次性复制到显示缓冲区。”
说白了,就是如果你只有一个缓冲区,那么在显示器刷新的时候很有可能把不完整的颜色缓冲传给渲染器进行渲染,导致画面撕裂;如果我们能开辟两个缓冲区,一个用于动态写入,另一个用来临时保存上一帧传输的颜色缓冲,那么在显示器刷新时,如果发现动态写入没有做完,就直接把暂存的上一帧的缓冲传给渲染器进行渲染,避免了闪烁、撕裂现象。这里我们就定义一个front,一个back。动态写入时我们往back里写,写完以后便换到front里暂存、传输,以此循环下去。
.h:
1 #ifndef PIPELINE_H
2 #define PIPELINE_H
3 #include "shader.h"
4 #include "framebuffer.h"
5 #include "matrix.h"
6
7 class Pipeline
8 {
9 private:
10 int width, height;
11 Shader *m_shader;
12 FrameBuffer *m_frontBuffer;
13 FrameBuffer *m_backBuffer;
14 std::vector<vertex> m_vertices;
15 std::vector<unsigned int=""> m_indices;
16 public:
17 enum ShadingMode{Simple,Gouraud,Phong};
18 enum RenderMode{Wire,Fill};
19 public:
20 Pipeline(int w,int h)
21 :width(w),height(h)
22 ,m_shader(nullptr),m_frontBuffer(nullptr)
23 ,m_backBuffer(nullptr){}
24 ~Pipeline();
25
26 void initialize();
27 void clearBuffer(const Vector4D &color, bool depth = false);
28 void setVertexBuffer(const std::vector<vertex> &vertices){m_vertices = vertices;}
29 void setIndexBuffer(const std::vector<unsigned int=""> &indices){m_indices = indices;}
30 void setShaderMode(ShadingMode mode);
31 void drawIndex(RenderMode mode);
32 void swapBuffer();
33 unsigned char *output(){return m_frontBuffer->getColorBuffer();}
34 };
35
36 #endif // PIPELINE_H
代码比较好理解,initialize就是为渲染管线的shader和双缓冲区申请空间,clearBuffer就是清空缓冲区,后面就是一堆设置的过程;drawIndex是真正的渲染管线流程,是最重要的一步;swapBuffer就是交换front和back,output则是返还front缓冲区的指针,供给渲染器进行渲染。
.cpp:
1 #include "basicshader.h"
2 #include "algorithm"
3 using namespace std;
4
5 Pipeline::~Pipeline()
6 {
7 if(m_shader)delete m_shader;
8 if(m_frontBuffer)delete m_frontBuffer;
9 if(m_backBuffer)delete m_backBuffer;
10 m_shader=nullptr;
11 m_frontBuffer=nullptr;
12 m_backBuffer=nullptr;
13 }
14
15 void Pipeline::initialize()
16 {
17 if(m_frontBuffer!=nullptr)delete m_frontBuffer;
18 if(m_backBuffer)delete m_backBuffer;
19 if(m_shader)delete m_shader;
20 m_frontBuffer=new FrameBuffer(width,height);
21 m_backBuffer=new FrameBuffer(width,height);
22 m_shader=new BasicShader();
23 }
24
25 void Pipeline::drawIndex(RenderMode mode)
26 {
27 if(m_indices.empty())return;
28 for(unsigned int i=0;i<m_indices.size() 3="">vertexShader(vv1),v2=m_shader->vertexShader(vv2),v3=m_shader->vertexShader(vv3);
29 m_backBuffer->Cover(static_cast<int>(v1.posV2P.x),static_cast<int>(v1.posV2P.y),v1.color);
30 m_backBuffer->Cover(static_cast<int>(v2.posV2P.x),static_cast<int>(v2.posV2P.y),v2.color);
31 m_backBuffer->Cover(static_cast<int>(v3.posV2P.x),static_cast<int>(v3.posV2P.y),v3.color);
32 /*这部分是光栅化*/
33 }
34 }
35
36 void Pipeline::clearBuffer(const Vector4D &color, bool depth)
37 {
38 (void)depth;
39 m_backBuffer->Fill(color);
40 }
41
42 void Pipeline::setShaderMode(ShadingMode mode)
43 {
44 if(m_shader)delete m_shader;
45 if(mode==Simple)
46 m_shader=new BasicShader();
47 /*else if(mode==Phong)
48 ;*/
49 }
50
51 void Pipeline::swapBuffer()
52 {
53 FrameBuffer *tmp=m_frontBuffer;
54 m_frontBuffer=m_backBuffer;
55 m_backBuffer=tmp;
56 }
其他函数都比较好理解,重点关注一下drawIndex函数,首先遍历所有的三角形,将各个三角形的顶点取出来后,分别使用着色器去进行处理。在2D渲染器可能看不出来处理的结果,但是在3D渲染器中这一步是不可或缺的。处理完以后呢,我们事先把三个点的颜色写入到对应的缓冲区中(放心,你肉眼应该看不见),接下来就是进行光栅化(画线or填充)了,因为这部分涉及到几个光栅化算法,篇幅较长,因此我决定放在下一篇详述。最后提醒一点,一定要注意内存管理,初始化时不要忘记动态申请空间,删除时不要忘记回收空间,我在这里runtime error爆了好几次。
至此,渲染管线的搭建就基本完成了,接下来我们进入到光栅化的核心部分——光栅化篇。
光栅化
上一节我们完成了渲染管线的搭建。该渲染管线是一个高度简化过的管线,只保留了传入模型网格、简单顶点着色、简单片元着色、光栅化写入双缓冲这几个步骤。由于上篇的篇幅较长,因此把光栅化的具体算法留在本篇来讲。
我们一共要完成两部分内容:分别是已知两个点,绘制其中的直线(画线操作)、已知三角形的三个点,填充三角形内部像素(填充操作)。
插值lerp
我们现有的顶点数量有限,但需要光栅化出来的像素数量却非常多,其中有很多像素是通过顶点数据插值得出来的,因此我们需要再补充一个lerp函数,用来对V2F类型的顶点做插值,其中要涉及V2F中的所有属性(包括各个空间的位置、颜色、法线、uv)
1 V2F Pipeline::lerp(const V2F &n1, const V2F &n2, float weight)
2 {
3 V2F result;
4 result.posV2P=n1.posV2P.lerp(n2.posV2P,weight);
5 result.posM2W=n1.posM2W.lerp(n2.posM2W,weight);
6 result.color=n1.color.lerp(n2.color,weight);
7 result.normal = n1.normal.lerp(n2.normal, weight);
8 result.texcoord = n1.texcoord.lerp(n2.texcoord, weight);
9 //result.oneDivZ=(1.0-weight)*n1.oneDivZ+weight*n2.oneDivZ;
10 result.textureID=n1.textureID;
11 return result;
12 }
bresenham算法
首先是画线操作。直线一共有4种基础状态,分别是横线、竖线和两种45°角的斜线:
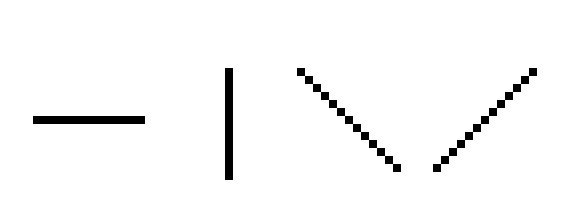
既然要画线,我们就必须要得出直线的函数表达式。斜截式(y=kx+b)是我们最熟悉的直线公式,只要我们给出一个x,就能得到相应的y值。但是在图2种,很显然给出一个x,我们得到的是无数个y,导致这个问题出现的原因是没有正确的选择自变量。
上述图中,图1必须让x作为自变量,y作为因变量;图2必须让y作为自变量,x作为因变量;图3、图4则随意。不难总结出以下判断方式:计算两点之间的横坐标差值△x和纵坐标差值△y,比较一下|△x|和|△y|之间的大小,若|△x|更大,则以x为自变量;否则以y作为自变量。
对于上述四张图而言,只要写出对应的y=kx+b或x=my+n即可精确的定位每个像素的位置,但是对于下述两张图而言会出现新的问题:
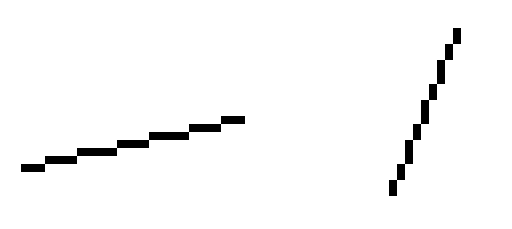
由于电脑显示器的精度有限,我们不可能让直线做到完全平滑,对于非45°角的斜线便会出现不同自变量对应相同因变量的现象,称作“直线走样”。当然为了解决这个问题会有相应的反走样和抗锯齿技术,但不是本节重点,先暂且不提。
首先我们看图1,很显然|△x|>|△y|,选择x为自变量,我们来分析其中的细节部分:
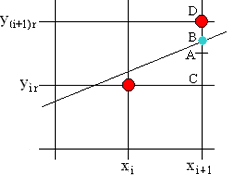
当我们扫描x到了$x_{i+1}$点时,通过解析式算出的y值并没有落在整数点上(如图的B点),由于屏幕分辨率的限制,我们只能选择在C点或在D点上进行绘制。我们取C和D连线的中点A作为分界,若B的y值大于A则绘制D点,否则绘制C点。
具体算法如下:首先我们规定x的步长为sx=1,y的步长为sy=k(即斜率)。为了方便计算,我们先把y值舍去小数部分取整,这样默认落在了C点上,然后直接取(B的y值)-(A的y值)作为$x_{i+1}$点的偏移量,写作ε($x_{i+1}$)。ε($x_{i+1}$)>0则将y值增加一个像素单位长度,否则不变。公式即为ε($x_{i+1}$)=BC-AC=($y_{i+1}$-$y_{ir}$)-0.5。
为了简化运算,我们可以迭代出ε($x_{i+k}$)的值。
ε($x_{i+2}$)=($y_{i+2}$-$x_{(i+1)r}$)-0.5
=$y_{i+1}$+sy-$y_{(i+1)r}$-0.5
=ε($x_{i+1}$)+$y_{ir}$-$y_{(i+1)r}$
以此类推下去:
ε($x_{i+3}$)=ε($x_{i+2}$)+sy+$y_{(i+1)r}$-$y_{(i+2)r}$
...
ε($x_{i+k}$)=ε($x_{i+k-1}$)+sy+$y_{(i+k-2)r}$-$y_{(i+k-1)r}$
个人认为$y_{(i+k-2)r}$-$y_{(i+k-1)r}$这个式子摆在这里很碍眼,不妨直接分类讨论:
若ε($x_{i+k-1}$)<0,则$y_{(i+k-2)r}$-$y_{(i+k-1)r}$=0:ε($x_{i+k}$)=ε($x_{i+k-1}$)+sy
若ε($x_{i+k-1}$)≥0,则$y_{(i+k-2)r}$-$y_{(i+k-1)r}$=-1:ε($x_{i+k}$)=ε($x_{i+k-1}$)+sy-1
现在递推公式求出来了,基本就可以编程了。但是,事实上我们可以避免浮点运算,只需要进一步优化一下公式。对于起点s而言,有:
①ε($x_{s+1}$)=sy-0.5
②ε($x_{i+k}$)=ε($x_{i+k-1}$)+sy。
③ε($x_{i+k}$)=ε($x_{i+k-1}$)+sy-1。
其中sy和0.5都是讨厌的浮点数,因此我们可以在左右都乘一个2△x(两个目标点的横坐标差),这样公式也就变成了:
①2△xε($x_{s+1}$)=2△y-△x
②2△xε($x_{i+k}$)=2△xε($x_{i+k-1}$)+2△y
③2△xε($x_{i+k}$)=2△xε($x_{i+k-1}$)+2△y-2*△x
将2△xε统一写成d,则递推式变为:
②d=d+2△y
③d=d+2△y-2△x
注意d=2△x*ε,我们默认△x>0,因此d和ε具有相同的符号。之前我们说当ε≥0时则y值增加,现在我们也可以说d≥0则y值增加。
整理一下,也就是说我们只需要维护一个d值,初始情况下d=2△y-△x,接下来每次迭代都需要判断一下d的大小,d<0的话则d=d+2△y;d>0的话则d=d+2△y-2△x并且y要增加1个单位,注意每次迭代都要给x++。这部分代码非常简洁,所以我也就不放伪代码了。要注意的是上述我们默认了△x>0,其实存在这样一种情况:x1
最后不要忘了在写入缓冲区的时候,颜色等信息都要取两点之间的插值。因此在传入函数时,我们不能仅仅传入两个坐标,而是要把经过着色器运算的这两个顶点整体传入:
1 void Pipeline::bresenham(const V2F &from, const V2F &to)
2 {
3 int dx=to.x-from.x,dy=to.y-from.y;
4 int sx=1,sy=1;
5 int nowX=from.x,nowY=from.y;
6 if(dx<0){
7 sx=-1;
8 dx=-dx;
9 }
10 if(dy<0){
11 sy=-1;
12 dy=-dy;
13 }
14 Vector4D tmp;
15 if(dy<=dx)
16 {
17 int d=2*dy-dx;
18 for(int i=0;i<=dx;++i)
19 {
20 tmp=lerp(from,to,static_cast<double>(i)/dx);
21 m_backBuffer->Cover(nowX,nowY,m_shader->fragmentShader(tmp));
22 nowX += sx;
23 if(d<=0)d+=2*dy;
24 else{
25 nowY+=sy;
26 d+=2*dy-2*dx;
27 }
28 }
29 }
30 else
31 {
32 int d=2*dx-dy;
33 for(int i=0;i<=dy;++i)
34 {
35 tmp=lerp(from,to,static_cast<double>(i)/dy);
36 m_backBuffer->Cover(nowX,nowY,m_shader->fragmentShader(tmp));
37 nowY += sy;
38 if(d<0)d+=2*dx;
39 else{
40 nowX+=sx;
41 d-=2*dy-2*dx;
42 }
43 }
44 }
45 }
栅栏填充算法
上面我们完成了直线绘制,接下来我们进行三角形内部填充。接下来要说的这个算法没找到它的学名是什么,所以直接按照自己的理解起了“栅栏填充”这么个名字。算法方法很简单,不需要像上面那个算法那样推导迭代,直接说思路:
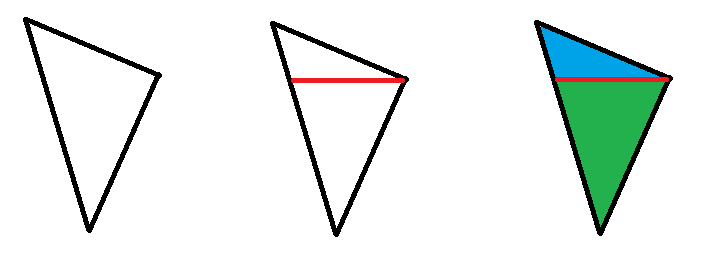
一张图直接说明算法核心。对于任意三角形,我们从y值处于中间的那个点做一个横线,将三角形一分为二,分为平底和平顶三角形。对于上面的平底三角形,我们只需要找到最上面的点,以它为起点向下迭代,每一行都画一条横线即可。
可能大家会有一个问题,理论上来说这个算法应该比画线要更复杂吧,毕竟三角形边框也是线做成的,为什么我们反而没有那么大计算量呢?事实上我们用这种朴素算法画出来的边框一定是严重走样的,比上述的Bresenhan算法的效果要差很多,但是因为填充的面积非常大,所以让观察者会忽略边框的锯齿走样。(事实上你在这个算法上做做改进,用Bresenhan算法先把边框描出来再根据边框位置进行填充也完全ok,但开销不太值得)
所以思路就是,首先我们将三角形进行分割为两个标准三角形,对于其中每个三角形,找出填充的y值范围;对于每一行而言,我们通过插值来获取横线的左端点和右端点信息(不仅是坐标,还要有颜色、法线等信息),接下来再画横线。画横线的过程别忘了也要对每个点做插值。
void Pipeline::scanLinePerRow(const V2F &left, const V2F &right)
{
V2F current;
int length = right.posV2P.x - left.posV2P.x + 1;
for(int i = 0;i <= length;++i)
{
// linear interpolation
double weight = static_cast<double>(i)/length;
current = lerp(left, right, weight);
current.posV2P.x = left.posV2P.x + i;
current.posV2P.y = left.posV2P.y;
// fragment shader
m_backBuffer->Cover(current.posV2P.x, current.posV2P.y,
m_shader->fragmentShader(current));
}
}
void Pipeline::rasterTopTriangle(V2F &v1, V2F &v2, V2F &v3)
{
V2F left = v2;
V2F right = v3;
V2F dest = v1;
V2F tmp, newleft, newright;
if(left.posV2P.x > right.posV2P.x)
{
tmp = left;
left = right;
right = tmp;
}
int dy = left.posV2P.y - dest.posV2P.y + 1;
for(int i = 0;i < dy;++i)
{
double weight = 0;
if(dy != 0)
weight = static_cast<double>(i)/dy;
newleft = lerp(left, dest, weight);
newright = lerp(right, dest, weight);
newleft.posV2P.y = newright.posV2P.y = left.posV2P.y - i;
scanLinePerRow(newleft, newright);
}
}
void Pipeline::rasterBottomTriangle(V2F &v1, V2F &v2, V2F &v3)
{
V2F left = v1;
V2F right = v2;
V2F dest = v3;
V2F tmp, newleft, newright;
if(left.posV2P.x > right.posV2P.x)
{
tmp = left;
left = right;
right = tmp;
}
int dy = dest.posV2P.y - left.posV2P.y + 1;
for(int i = 0;i < dy;++i)
{
double weight = 0;
if(dy != 0)
weight = static_cast<double>(i)/dy;
newleft = lerp(left, dest, weight);
newright = lerp(right, dest, weight);
newleft.posV2P.y = newright.posV2P.y = left.posV2P.y + i;
scanLinePerRow(newleft, newright);
}
}
void Pipeline::edgeWalkingFillRasterization(const V2F &v1, const V2F &v2, const V2F &v3)
{
V2F tmp;
V2F target[3] = {v1, v2,v3};
if(target[0].posV2P.y > target[1].posV2P.y)
{
tmp = target[0];
target[0] = target[1];
target[1] = tmp;
}
if(target[0].posV2P.y > target[2].posV2P.y)
{
tmp = target[0];
target[0] = target[2];
target[2] = tmp;
}
if(target[1].posV2P.y > target[2].posV2P.y)
{
tmp = target[1];
target[1] = target[2];
target[2] = tmp;
}
if(target[0].posV2P.y==target[1].posV2P.y){
rasterBottomTriangle(target[0],target[1],target[2]);
}
else if(target[1].posV2P.y==target[2].posV2P.y){
rasterTopTriangle(target[0], target[1], target[2]);
}
else
{
double weight = static_cast<double>(target[1].posV2P.y-target[0].posV2P.y)/(target[2].posV2P.y-target[0].posV2P.y);
V2F newPoint = lerp(target[0],target[2],weight);
newPoint.posV2P.y = target[1].posV2P.y;
rasterTopTriangle(target[0], newPoint, target[1]);
rasterBottomTriangle(newPoint,target[1],target[2]);
}
}
至此,光栅化的关键算法我们就完成了。
网格体类
之前我们在渲染管线中声明了一系列的顶点和顶点索引,我们可以使用这两个数据来进行光栅化操作,但现在的问题是这两个数据从哪来?但凡对于游戏制作方面有点了解的朋友都知道,来自于模型文件。所以除此之外,我们需要再定义一个新的类——mesh类来存储顶点信息和索引。
1 class Mesh
2 {
3 public:
4 std::vector<Vertex> vertices;
5 std::vector<unsigned int> index;
6
7 Mesh(){}
8 ~Mesh(){}
9
10 Mesh(const Mesh& msh):vertices(msh.vertices),index(msh.index){}
11 Mesh& operator=(const Mesh& msh);
12 void setVertices(Vertex* v, int count);
13 void setIndex(int* i, int count);
14
15 void triangle(Vector3D &v1,Vector3D &v2,Vector3D &v3);
16 void pyramid();
17 void cube(double width, double height, double depth, int id, Vector4D pos);
18 void plane(double width,double height,int id,Vector4D pos);
19 };
这里我们定义了顶点组和索引组,同时也定义了几个给自己初始化的函数,例如triangle函数,它的作用就是存储传入顶点的信息,并完成索引、法线、颜色等赋值。.cpp文件如下:
void Mesh::setVertices(Vertex* v, int count)
{
vertices.resize(static_cast<unsigned long>(count));
new(&vertices[0])std::vector<Vertex>(v,v+count);
}
void Mesh::setIndex(int* i, int count)
{
index.resize(static_cast<unsigned long>(count));
new(&index)std::vector<unsigned int>(i,i+count);
}
void Mesh::triangle(Vector3D &v1, Vector3D &v2, Vector3D &v3)
{
vertices.resize(3);
index.resize(3);
vertices[0].position=v1;
vertices[0].normal=Vector3D(0.f,0.f,1.f);
vertices[0].color=Vector4D(1.f,0.f,0.f,1.f);
vertices[0].texcoord=Vector2D(0.f,0.f);
vertices[1].position=v2;
vertices[1].normal=Vector3D(0.f,0.f,1.f);
vertices[1].color=Vector4D(0.f,1.f,0.f,1.f);
vertices[1].texcoord=Vector2D(1.f,0.f);
vertices[2].position=v3;
vertices[2].normal=Vector3D(0.f,0.f,1.f);
vertices[2].color=Vector4D(0.f,0.f,1.f,1.f);
vertices[2].texcoord=Vector2D(0.5f,1.f);
index[0]=0;
index[1]=1;
index[2]=2;
}
渲染循环附件
目前我们缺少一个系统将管线各功能串联起来,并将讯息传送给画布,本篇我们的目的就是要构造一个这样的系统,我称之为renderRoute,即渲染循环的意思。它的作用主要有两部分,第一是储存待渲染的对象,然后逐步调用渲染管线类中的方法完成渲染;第二是在渲染结束的时候将讯息及时送往渲染器窗口mainwindow。
为了提升效率,就不再一点点分析怎么去设计了,直接上头文件:
1 #ifndef RENDERROUTE_H
2 #define RENDERROUTE_H
3 #include"QObject"
4 #include "pipeline.h"
5
6 class RenderRoute:public QObject
7 {
8 Q_OBJECT
9 public:
10 explicit RenderRoute(int w,int h,QObject *parent=nullptr);
11 ~RenderRoute(){}
12 void stopIt();
13 signals:
14 void frameOut(unsigned char *image);
15
16 public slots:
17 void loop();
18
19 private:
20 bool stopped;
21 int width,height,channel;
22 Pipeline *pipeline;
23 };
24
25 #endif
首先最基础的,我们定义了一个管理渲染状态的bool值stopped,然后定义了画布的属性:宽、高、通道数(不出意外都是4,除非是灰度图),然后定义了一个管理的对象Pineline。函数方面,首先声明了个构造函数和析构函数,然后定义了一个用来暂停的函数stopIt。frameout是一种信号函数,这个我们下文再解释。最后的loop则是我们的核心函数,表明渲染循环开始执行,它是由mainwindow来操纵的。
接下来我们来详细看各个函数,首先是构造函数:
1 RenderRoute::RenderRoute(int w, int h, QObject *parent)
2 : QObject(parent), width(w), height(h), channel(4)
3 {
4 stopped=false;
5 pipeline=new Pipeline(width, height);
6 }
7
8 void RenderRoute::stopIt(){
9 stopped=true;
10 }
构造函数就是初始化的过程,先把stopped归为false表明渲染进行中,然后就是要给pipeline对象申请内存并初始化,将渲染管线中的宽高也置为渲染循环默认的宽高。stopIt函数就不解释了。下面来看一下最关键的渲染函数loop:
1 void RenderRoute::loop()
2 {
3 pipeline->initialize();
4 Vector3D v1(100,100,0),v2(1200,200,0),v3(500,700,0);
5 Mesh *msh=new Mesh;
6 msh->triangle(v1,v2,v3);
7 pipeline->setVertexBuffer(msh->vertices);
8 pipeline->setIndexBuffer(msh->index);
9 while(!stopped)
10 {
11 pipeline->clearBuffer(Vector4D(0,0,0,1.0f));
12 pipeline->drawIndex(Pipeline::Fill);
13 pipeline->swapBuffer();
14 emit frameOut(pipeline->output());
15 }
16 }
上文我们提到,渲染循环是存储基础数据的地方。因此在这里,我们必须把每帧要渲染的对象数据给出。在对渲染管线对象进行初始化(各种申请空间)后,我们便给出待渲染对象:一个三角形模型。三角形模型本质上就是三个点,因此直接创建三个Vector类型的对象,调用mesh类对象的triangle方法,传入三个顶点,这样我们就可以得到一个完整的顶点数组和序号数组,然后再将它们传入pipeline中作预备。
当我们成功把数据导入渲染管线后,若渲染未被停止,则开始调用渲染管线类中的方法——首先是清空缓冲区,将所有颜色都归为黑色,然后调用drawIndex来进行几何处理、着色器计算和光栅化操作。接下来颜色数据已经放入到back缓冲区中了,我们要手动调换front和back缓冲区,让已经渲染完成的颜色数据进入待命状态。上述步骤全部完成之后,我们便发射信号:emit frameOut(pipeline->output()),将渲染管线中front缓冲区中的颜色数据发射出去。
多线程通讯
最后一步,便是完成mainwindow类的最后一点配置。上文我们提到渲染循环renderRoute会将front的缓存数据发射出去。有发射就得有接收,这里我们定义一个接受信号函数receiveFrame:
1 void MainWindow::receiveFrame(unsigned char *data)
2 {
3 if(canvas) delete canvas;
4 canvas = new QImage(data, width(), height(), QImage::Format_RGBA8888);
5 update();
6 }
这里就是说当我们拿到了需要渲染的颜色缓存数据后,将旧的画布删掉,创建一个新的画布后进行update更新操作。在帧缓冲那一节,我们override了一个paintEvent函数,是真正的渲染操作,而它就是update中的一步。因此整件事的逻辑顺序就是:renderRoute渲染完成,发射信号,mainwindow接收到颜色数据,重置画布,调用update函数,update中会自动调用paintEvent函数,来完成渲染。
这样,我们的整个渲染操作的思路就全部理完了。最后还差什么呢,一是信号连接,二是多线程,这里我们直接把两部分合在一起:
1 MainWindow::MainWindow(QWidget *parent)
2 : QMainWindow(parent)
3 , ui(new Ui::MainWindow)
4 {
5 ui->setupUi(this);
6 this->resize(1280,768);
7 loop=new RenderRoute(width(),height(),nullptr);
8 loopThread=new QThread(this);
9 loop->moveToThread(loopThread);
10 connect(loopThread,&QThread::finished,loop, &RenderRoute::deleteLater);
11 connect(loopThread,&QThread::started,loop,&RenderRoute::loop);
12 connect(loop,&RenderRoute::frameOut,this,&MainWindow::receiveFrame);
13 loopThread->start();
14 }
15
16 MainWindow::~MainWindow()
17 {
18 delete ui;
19 loop->stopIt();
20 loopThread->quit();
21 loopThread->wait();
22 if(canvas)delete canvas;
23 if(loopThread)delete loopThread;
24 loop=nullptr;
25 canvas=nullptr;
26 loopThread=nullptr;
27 }
首先在构造函数中,我们先声明ui(固定操作,不用搞懂它是干嘛的),设置默认窗口大小,然后我们创建一个渲染循环实例,一个渲染多线程。moveToThread可以将对象自身移交到多线程对象中,这样它的所有函数方法都会使用多线程来调用,然后就是三个连接:第一个连接,声明了多线程的结束条件;第二个连接,声明了多线程开始的时候要调用的渲染循环的方法;第三个连接,就是将发射信号和接收信号链接在一起,这样发射信号的函数可以精准无误地把讯息送到接收信号的函数中。
当一切都准备完毕后,便可以开启多线程了。此时,渲染循环就会逐帧运作,将内部的数据信息通过渲染管线类来完成计算和光栅化等操作。mainwindow还需要详细写一下析构函数,因为线程必须要及时停止或结束,然后释放空间,指针归位等等。至此,我们2D渲染的部分就完成了。

原文链接: https://www.cnblogs.com/puluoji/p/14727595.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍
原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/210173
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!