
简介
pcm 全称为 Performance Counter Monitor,该项目是针对 intel 平台处理器的资源利用率进行监控的工具。在现代 Intel 处理器已经提供了监视处理器内部性能事件的功能,pcm 通过读取性能监视单元(PMU),从而获得的动态数据。
pcm-pcie.x 运行
pcm-pcie.x 为 pcm 软件中监控 pcie 带宽工具。软件运行时需要 root 权限,在当前平台(Cascade Lake)可以输出包括如下指标内容。
| 监控指标 | 缩写 | 指标介绍 |
|---|---|---|
| PCIRdCur_miss/PCIRdCur_hit | PCIRdCur | PCIe read current transfer (full cache line)(PCIe 设备从系统内存读取) |
| RFO_miss/RFO_hit | RFO | Demand Data RFO(PCIe 设备写入系统内存部分 cache line) |
| CRd_miss/CRd_hit | CRd | Demand Code Read(与PCIRdCur不同的PCIe读取流) |
| DRd_miss/DRd_hit | DRd | Demand Data Read(与PCIRdCur不同的PCIe读取流) |
| ItoM_miss/ItoM_hit | ItoM | PCIe write full cache line(PCIe 设备写入系统内存完整 cache line) |
| PRd_miss/PRd_hit | PRd | MMIO Read [Haswell Server only] (Partial Cache Line)(CPU 通过MMIO模式从设备内存读取) |
| WiL_miss/WiL_hit | WiL | MMIO Write (Full/Partial)(CPU 通过MMIO模式写入设备内存) |
除此之外,pcm-pcie.x 还支持使用参数 -B 输出 PCIe 总读写带宽
$ ./pcm-pcie.x -B
...
Detected Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz "Intel(r) microarchitecture codename Cascade Lake-SP" stepping 6 microcode level 0x4000017
Skt | PCIRdCur | RFO | CRd | DRd | ItoM | PRd | WiL | PCIe Rd (B) | PCIe Wr (B)
0 18 K 2478 0 0 826 2688 1092 1313 K 211 K
1 0 0 0 0 0 2282 560 0 0
--------------------------------------------------------------------------------------------------
* 18 K 2478 0 0 826 4970 1652 1313 K 211 K
pcm-pcie 代码
下面将对 Cascade Lake 平台上 pcm-pcie.x 运行过程进行介绍。
初始化
在 purley 平台,通过以下代码生成对应平台 platform 指针
unique_ptr<IPlatform> platform(IPlatform::getPlatform(
m, csv, print_bandwidth, print_additional_info,
(uint)delay)); // FIXME: do we support only integer delay?
这句话声明了一个 unique_ptr<IPlatform> 类型指针,初始化使用 IPlatform 的静态函数 IPlatform::getPlatform 执行。在 purley 平台,IPlatform::getPlatform 会返回 PurleyPlatform 类型对象,因此需要对类的初始化进一步查看。
PurleyPlatform 类型继承自 LegacyPlatform,因此其初始化过程主要使用后者的初始化函数作为初始化列表。
PurleyPlatform(PCM *m, bool csv, bool bandwidth, bool verbose, uint32 delay) :
LegacyPlatform( {"PCIRdCur", "RFO", "CRd", "DRd","ItoM", "PRd", "WiL"},
{
{0x00043c33}, //PCIRdCur_miss
{0x00043c37}, //PCIRdCur_hit
{0x00040033}, //RFO_miss
{0x00040037}, //RFO_hit
{0x00040233}, //CRd_miss
{0x00040237}, //CRd_hit
{0x00040433}, //DRd_miss
{0x00040437}, //DRd_hit
{0x00049033}, //ItoM_miss
{0x00049037}, //ItoM_hit
{0x40040e33}, //PRd_miss
{0x40040e37}, //PRd_hit
{0x40041e33}, //WiL_miss
{0x40041e37}, //WiL_hit
},
m, csv, bandwidth, verbose, delay)
{
};
在 LegacyPlatform 输入参数中,除了 PurleyPlatform 输入参数外,还多了两个常量数组,分别赋值给 eventNames 和 eventGroups 属性。其中传入的 eventNames 代表监控事件的简称,而 eventGroups 对应了监控事件的编码。注意,此编码既不是监控事件对应的 event 或 umask 编码,也不是 filter 的操作码,而是三个编码的集合。后面将在函数 PCM::programPCIeEventGroup 内通过对此编码进行操作,最终得到对应监控事件的所需的所有信息。
指标监控
监控过程中,调用 platform->getEvents() 方法获取所有监控指标的信息。检查 LegacyPlatform::getEvents() 方法可以发现,运行过程中对 eventGroups 数组中每个监控指标调用函数 getEventGroup 采集,最终获取监控指标后保存。
函数 LegacyPlatform::getEventGroup 具体内容为:
void LegacyPlatform::getEventGroup(eventGroup_t &eventGroup)
{
m_pcm->programPCIeEventGroup(eventGroup);
uint offset = eventGroupOffset(eventGroup);
for (auto &run : eventCount) {
for(uint skt =0; skt < m_socketCount; ++skt)
for (uint ctr = 0; ctr < eventGroup.size(); ++ctr)
run[skt][ctr + offset] = m_pcm->getPCIeCounterData(skt, ctr);
MySleepMs(m_delay);
}
for(uint skt = 0; skt < m_socketCount; ++skt)
for (uint idx = offset; idx < offset + eventGroup.size(); ++idx)
eventSample[skt][idx] += getEventCount(skt, idx);
}
其中第一个循环为监控循环,第二个获取监控数据。eventCount 为长度为 2 的数组 std::array ,分别储存一段时间间隔前后监控信息。所以,整个监控过程其实按照(1)监控指标循环(2)监控步(3)socket(4)监控指标个数(1个)进行循环。
监控事件指定
在 LegacyPlatform::getEventGroup 函数每次监控前,首先需要调用 programPCIeEventGroup(eventGroup) 指定对应监控事件。
在 PCM::programPCIeEventGroup 函数内,针对 CascadeLake 平台执行主要指令如下:
case PCM::SKX:
// JKT through СLX generations allow programming only one required event
// at a time.
if (eventGroup[0] & SKX_CHA_MSR_PMON_BOX_FILTER1_NC(1))
umask[0] |= (uint64)(SKX_CHA_TOR_INSERTS_UMASK_IRQ(1));
else
umask[0] |= (uint64)(SKX_CHA_TOR_INSERTS_UMASK_PRQ(1));
if (eventGroup[0] & SKX_CHA_MSR_PMON_BOX_FILTER1_RSV(1))
umask[0] |= (uint64)(SKX_CHA_TOR_INSERTS_UMASK_HIT(1));
else
umask[0] |= (uint64)(SKX_CHA_TOR_INSERTS_UMASK_MISS(1));
events[0] +=
CBO_MSR_PMON_CTL_EVENT(0x35) + CBO_MSR_PMON_CTL_UMASK(umask[0]);
programCbo(events, SKX_CHA_MSR_PMON_BOX_GET_OPC0(eventGroup[0]),
SKX_CHA_MSR_PMON_BOX_GET_NC(eventGroup[0]));
break;
可以看出,对于每个输入的 eventGroup 数组,由于其长度仅为 1,因此在使用时直接将其赋值在 events[0] 上,随后调用 programCbo 函数对控制寄存器进行编程。
在 programCbo 函数中,需要对 filter 和 cbo 控制寄存器进行分别赋值。为了后面描述方便,先展示详细代码如下所示:
for (size_t i = 0; (i < cboPMUs.size()) && MSR.size(); ++i)
{
uint32 refCore = socketRefCore[i];
// std::cout << "cboPMUs info: n"
// << "tcboPMUs index: " << i << "n"
// << "tref core ind: " << refCore << std::endl;
TemporalThreadAffinity tempThreadAffinity(
refCore); // speedup trick for Linux
for (uint32 cbo = 0; cbo < getMaxNumOfCBoxes(); ++cbo)
{
cboPMUs[i][cbo].freeze(UNC_PMON_UNIT_CTL_FRZ_EN);
programCboOpcodeFilter(opCode, cboPMUs[i][cbo], nc_, 0, loc, rem);
if ((HASWELLX == cpu_model || BDX_DE == cpu_model || BDX == cpu_model ||
SKX == cpu_model) &&
llc_lookup_tid_filter != 0)
*cboPMUs[i][cbo].filter[0] = llc_lookup_tid_filter;
for (int c = 0; c < 4; ++c)
{
*cboPMUs[i][cbo].counterControl[c] = CBO_MSR_PMON_CTL_EN;
*cboPMUs[i][cbo].counterControl[c] = CBO_MSR_PMON_CTL_EN + events[c];
}
cboPMUs[i][cbo].resetUnfreeze(UNC_PMON_UNIT_CTL_FRZ_EN);
for (int c = 0; c < 4; ++c)
{
*cboPMUs[i][cbo].counterValue[c] = 0;
}
}
}
在上面代码中,有两个主要循环,分别是对 cboPMUs 对象和 cbo 循环。cboPMUs 对象个数和节点内 socket 个数相同,对于每个 socket 会生成一个对应 cboPMUs 进行操作。在 uncore 中 CBox(cbo)个数则与每个 CPU 包含的物理核心数完全相同,并且在 SkyLake 和 CascadeLake 平台,还需要判断在 CPU 内 28 个可用 CHA 哪些是开启的。
通过输入的 filter 操作码和对应的 cbo 对象,programCboOpcodeFilter 函数将监控的操作码写入 filter 控制寄存器中。随后,在通过 cboPMUs[i][cbo].counterControl[c] 对象将事件号写入控制寄存器。需要指出的是,尽管下面代码对 4 个控制集群器都进行了编码,但是其实仅有 enents[0] 对应的编号不为0。
for (int c = 0; c < 4; ++c)
{
*cboPMUs[i][cbo].counterControl[c] = CBO_MSR_PMON_CTL_EN;
*cboPMUs[i][cbo].counterControl[c] = CBO_MSR_PMON_CTL_EN + events[c];
}
监控事件对应指标
通过在代码中加入相应输出内容,我们可以得到不同事件的监控对应的事件、掩码和filter操作码。在intel官方手册 Skylake Uncore Performance Monitoring 中,对不同的 filter 操作码进行了介绍,如下表所示。
| name | event | umask | opc0 | description |
|---|---|---|---|---|
| PCIRdCur_miss | 35 | 24 | 21e | Read current • Read Current requests from IIO. Used to read data without changing state. |
| PCIRdCur_hit | 35 | 14 | 21e | |
| RFO_miss | 35 | 24 | 200 | Demand Data RFO • Read for Ownership requests from core for lines to be cached in E. |
| RFO_hit | 35 | 14 | 200 | |
| CRd_miss | 35 | 24 | 201 | Demand Code Read • Full cache-line read requests from core for lines to be cached in S, typically for code. |
| CRd_hit | 35 | 14 | 201 | |
| DRd_miss | 35 | 24 | 202 | Demand Data Read • Full cache-line read requests from core for lines to be cached in S or E, typically for data. |
| DRd_hit | 35 | 14 | 202 | |
| ItoM_miss | 35 | 24 | 248 | Request Invalidate Line • Request Exclusive Ownership of cache line. |
| ItoM_hit | 35 | 14 | 248 | |
| PRd_miss | 35 | 21 | 207 | Partial Reads (UC) • Partial read requests of 0-32B (IIO can be up to 64B). Uncacheable. |
| PRd_hit | 35 | 11 | 207 | |
| WiL_miss | 35 | 21 | 20f | Write Invalidate Line - Partial |
| WiL_hit | 35 | 11 | 20f |
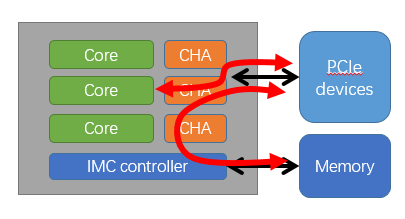

在 PCIE 读取数据时,包含上图中描述的两种数据流动。
- 第一种是 CPU 直接对 PCIe 数据进行读写操作,而监控指标 PRd 和 WiL 分别监控 CPU 以 MMIO 模式读写过程;
- 第二种则为 PCIe 设备对内存数据读写操作,PCIeRdCur 为 PCIe 设备对内存数据读操作,而 ItoM 和 RFO 则为对内存数据的写操作。
总结
在本文中,对 pcm-pcie.x 程序运行主要过程进行了解析,以上过程对于建立 Intel 平台 uncore 部分监控,特别是 PCIe 带宽监控具有一定的参考价值。
原文链接: https://www.cnblogs.com/li12242/p/13633233.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/202517
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!