
1. 正文
1.1. 任务划分
使用高通量计算第一步就是要针对密集运算任务做任务划分。将一个海量的、耗时的、耗资源的任务划分成合适粒度的小任务,需要综合考虑资源、数据等多方面因素。HTCondor并不参与这方面的工作,任务划分需要用户自己实现。
默认情况下,HTCondor会把一个CPU核心当成一个计算资源。最理想的情况,就是计算集群网络内所有的集群主机都是同样的配置,数据也是易于划分的,那么可以按照计算机集群内CPU的总核心数,对数据量等分划分。这样,因为同样的数据量同样的计算机资源,进行分布式计算时理论上会同时完成,也就达到了负载均衡。
这里就准备了这样的一个任务例子,假设任务已经划分好,已经放到同一个目录中:
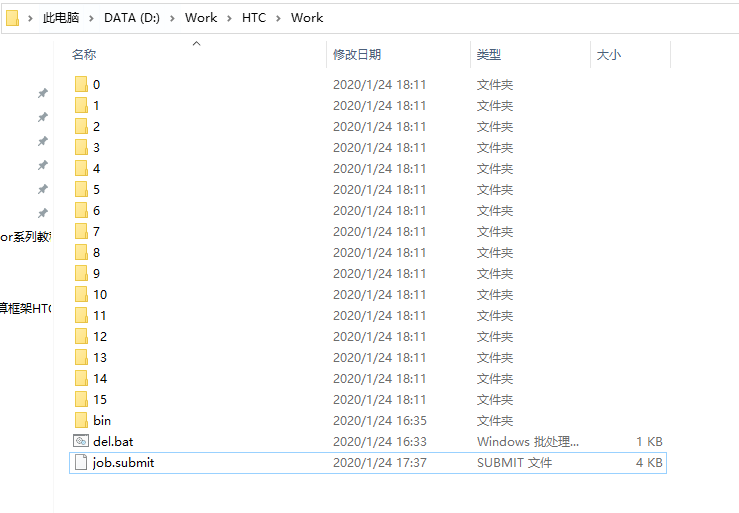

0,1,2,..., 15就是划分好的16份数据,每个目录中都存放了数据。所谓计算任务,就是输入一个数据,处理后形成新的数据。所以,每个文件夹都放入了一个input.txt文件,作为计算任务的输入:
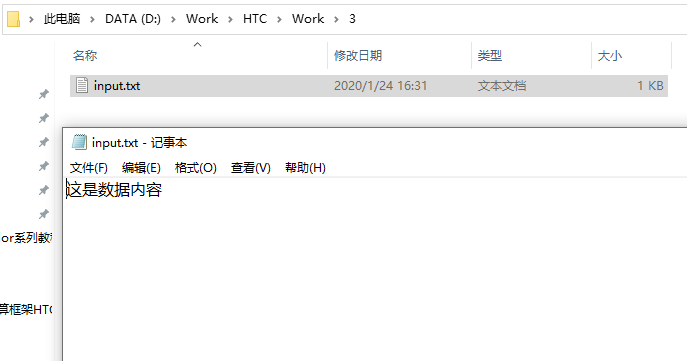
实例目的很简单,就是将这些划分好的任务提交到HTCondor,让HTCondor的计算资源分别处理这些数据,并将新的数据返回来。
1.2. 任务程序
既然要进行计算任务,那么不可或缺的就是运行的任务程序了。说到底分布式计算的基础还是单机运算,必须要保证发送的每个任务在单机下就能正确运行,才能谈任务调度的问题。
在这里我用的是一个C/C++的任务程序:
#include <iostream>
#include <fstream>
#include <string>
#include <time.h>
using namespace std;
int main()
{
fprintf(stdout, "开始运行n");
//延时10S
fprintf(stdout, "延时10Sn");
time_t first = time(NULL);
double diff = 0;
while (diff<10)
{
time_t second = time(NULL);
diff = difftime(second, first); //计时
}
ifstream infile("input.txt");
if (!infile)
{
fprintf(stderr, "无法读取文件n");
return 1;
}
string line;
getline(infile, line);
ofstream outfile("output.dat");
if (!outfile)
{
fprintf(stderr, "无法写出文件n");
return 1;
}
outfile << "输出内容:n";
outfile << line;
fprintf(stdout, "运行完成n");
return 0;
}
可以看到这个程序特别简单,就是延时10秒后,读取input.txt的内容,写出到output.dat中。延时10秒是为了方便显示运行状态。其实不必非要C/C++的程序,只要是能够运行的可执行程序即可,条件是每台机器要有对应的运行环境,否则发送过去的任务会因为无法运行而挂起。
将这个程序编译的可执行程序放到bin目录中,保证在单机的情况下,能够正常运行。
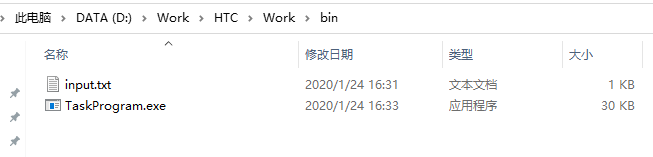
在下一章中,将会介绍如何通过HTCondor框架运行这个实例。
2. 相关
原文链接: https://www.cnblogs.com/charlee44/p/12232507.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/192306
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!