
前言
好久没写东西了,突发奇想,写写函数参数的压栈顺序
先看看这个问题
https://q.cnblogs.com/q/137133/
然后看我简化的代码,猜输出结果是多少?
#include<bits/stdc++.h>
using namespace std;
int main(){
int i=0;
printf("%d %d",i++,i--);
return 0;
}
根据++和--的特性,i++的时候数值不变,输出0,i--时i才加上1,输出1。
事实是这样吗?我在多台编译器上执行,输出的结果都是:
-1 0
栈
根据我之前写过的指针篇的内容,函数的局部变量保存在栈中,都是独立的,参数同样保存在栈中,才导致了swap函数改变函数参数必须使用指针。
那么,函数参数,在栈中是如何排列的呢?顺序?倒序?
我们写一个简短的代码,来实验一下。
#include<bits/stdc++.h>
using namespace std;
void test(int a,int b){
printf("a..%p, b..%p",&a,&b);
}
int main(){
int a,b;
test(a,b);
}
由于是地址,不同编译器的结果不同。但肯定的是,a比b大4。
如果多加几个变量进去,我们发现,地址的大小从大到小递减。
栈模型
图源:《征服C指针》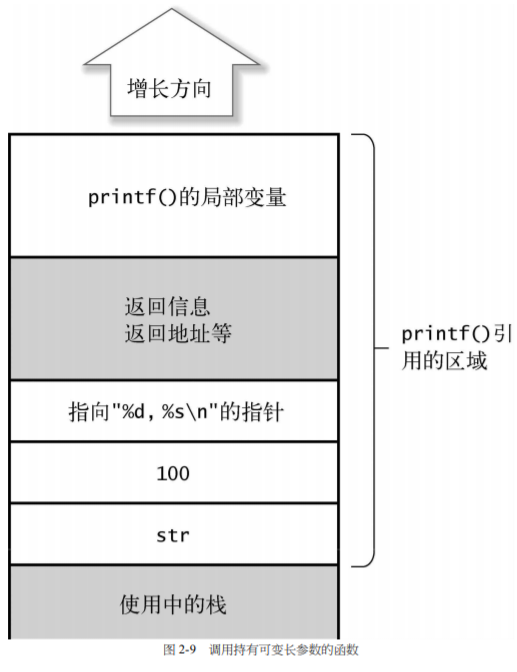

从这张图中可以看出,C语言中,参数是从后往前堆积在栈中的。这种处理方式的好处在于,无论有多少个参数,总能找到第一个参数的地址,这样就可以顺次找到后面的参数。否则,从后往前,就无法找到第一个参数,也无法实现可变长参数的功能。
例如在printf中,我们找到第一个参数的位置,例如"%d %s",就可以顺次解析后面的地址的参数,因为参数是连续在内存排列的。
问题解释
既然参数是从后往前放入栈中的,那么,我们就可以解释这个问题了。
#include<bits/stdc++.h>
using namespace std;
int main(){
int i=0;
printf("%d %d",i++,i--);
return 0;
}
开头的代码。如果编译成汇编语言进行执行,应该是这个样子(如果有错误请指正,手写的)
sub [i],1 ;i--
push [i]
add [i],1 ;i++
push [i]
push offset string "%d %d" ;"%d %d"
call dword ptr_printf ;调用printf
在汇编语言中,push是将参数压入栈的一个指令,由于这篇文章不是讲汇编的,大家看看就好。
因此,在推入栈的时候,先执行了i--,再执行i++,结果也当然是这样了。
原文链接: https://www.cnblogs.com/wl-blog/p/15814913.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍

原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/186205
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!