
(注:如有转载请标明作者:finallyliuyu, 和出处:博客园)
在《文本分类step by step(一)》中,我们从处理语料库开始讲起,一直讲到利用分类器进行分类。文章末尾还随机抽取了一篇文章,给出了这篇文章的标题、正文、实际类别,分类器所分类别等信息。在此篇博客中我们将介绍分类器的评估,以及代码的一些介绍,最后给出程序和实验语料库的下载地址。
(一)分类器评估
关于查准率,查全率,F值的定义以及的代码实现见博文《评估分类器》
主函数调用如下:

 计算准确率,召回率,F值map<string,vector<double>>evaluation;
计算准确率,召回率,F值map<string,vector<double>>evaluation;
for(vector<string>::iterator it=labels.begin();it!=labels.end();it++)
{
doubleprecision=p.getPrecision(it,classifyResults,"TestingCorpus");
doublerecall=p.getRecall(it,classifyResults,"TestingCorpus");
doubleF=p.getFscore(it,classifyResults,"TestingCorpus");
vector<double>temp;
temp.push_back(precision);
temp.push_back(recall);
temp.push_back(F);
evaluation[it]=temp;
temp.clear();
}
for(map<string,vector<double>>::iterator it=evaluation.begin();it!=evaluation.end();it++)
{
cout<<it->first<<endl;
cout<<"precison"<<(it->second)[0]<<endl;
cout<<"recall"<<(it->second)[1]<<endl;
cout<<"Fscore"<<(it->second)[2]<<endl;
cout<<"*******"<<endl;
}
doubleavaP=0.;//平均准确率
doubleavaR=0.;//平均召回率
doubleavaF=0.;//平均F值
for(map<string,vector<double>>::iterator it=evaluation.begin();it!=evaluation.end();it++)
{
avaP+=(it->second)[0];
avaR+=(it->second)[1];
avaF+=(it->second)[2];
}
cout<<evaluation.size();
avaP/=evaluation.size();
avaR/=evaluation.size();
avaF/=evaluation.size();
cout<<"平均准确率为"<<avaP<<endl;
cout<<"平均召回率"<<avaR<<endl;
cout<<"平均F值"<<avaF<<endl;
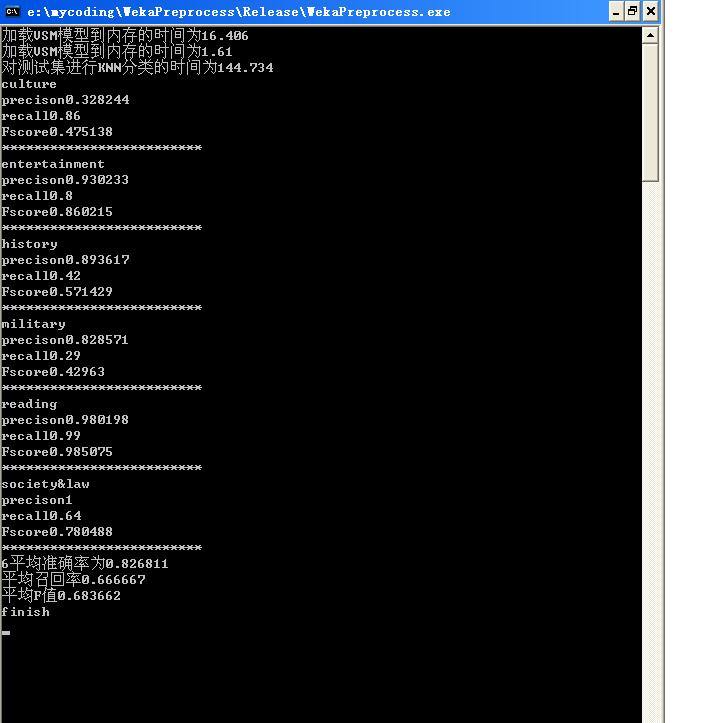
实验结果:
(二)代码说明:
运行的时候,采用release模式运行,debug模式下运行速度很慢
1.涉及数据库交互函数:数据库的链接字符串写死在了下列函数中,如果需要改变所链接数据库则在下列函数中修改链接字符串
涉及数据库交互操作的函数intConstructDictionary(DICTIONARY&mymap,FUNCSEG seg,stringtablename);
intGetArticleIdinEachClass(vector<string>labels,stringtablename,map<string,vector<int>>&articleIdinEachClass );
vector<string>GetClassification(stringarticleIds);//获得该篇文章对应的类别
stringGetCategorizationInfoById(intarticleId,stringtablename);
intPreprocess::GetManyVSM(intbegin,intend,stringtablename,DICTIONARY&mymap,DOCMATRIX&testingsetVSM,char*keywordsaddress)
2.涉及硬盘存取交互函数
涉及硬盘IO交互操作的函数//保存词袋子到硬盘
voidSaveDictionary(DICTIONARY&mymap,charaddress);
//从内存中加载词袋子模型
voidLoadDictionary(DICTIONARY&mymap,charaddress);
voidSaveContingencyTable(CONTINGENCY&contingencyTable,charaddress);
voidLoadContingencyTable(CONTINGENCY&contingencyTable,charaddress);
voidSaveVSM(DOCMATRIX&VSMmatrix,chardest);
voidLoadVSM(DOCMATRIX&VSMmatrix,chardest);
vector<string>GetFinalKeyWords(charaddress);
voidChiSquareFeatureSelection(vector<string>classLabels,DICTIONARY&mymap,CONTINGENCY&contingencyTable,intN,charaddress);
oid DFcharicteristicWordSelection(DICTIONARY&mymap,intDFthreshold,char*address);
3.分词
头文件中定义了一个指向指向类的成员函数的指针,分别指向两种不同的切分模式。其中一种切分模式调用计算所的ICTCLAS;另一种切分模式以空格作为分界符进行分割,对应的函数如下:
vector<string>goodWordsinPieceArticle(stringrawtext,set<string>stopwords);
vector<string>mySplit(strings,set<string>stopwords);//分割关键词
(三)资源下载地址(资源作者:finallyliuyu,空间提供方:博客园)
1.语料库资源 下载地址 注意:语料库为MSSQL2000备份格式,如何还原请大家自己查阅相关资料,网络上有很多这方面的知识也就不赘述了。
2. 程序资源下载地址程序包中目前有DF,chi-square特征词选择算法,以及KNN分类算法。如果时间允许,我会继续往程序包中添加 IG,point-wise MI特征词选择算法,以及多项式贝叶斯分类器。另外再次声明我是一个C++新手,编程有很多不规范的地方,希望不要误人子弟。另外,如果有高手愿意指教我会非常高兴。 目前程序是控制台程序,如果有人愿意用MFC编写演示界面,那就最好不过了。呵呵。
原文链接: https://www.cnblogs.com/finallyliuyu/archive/2010/09/29/1838745.html
欢迎关注
微信关注下方公众号,第一时间获取干货硬货;公众号内回复【pdf】免费获取数百本计算机经典书籍
原创文章受到原创版权保护。转载请注明出处:https://www.ccppcoding.com/archives/15635
非原创文章文中已经注明原地址,如有侵权,联系删除
关注公众号【高性能架构探索】,第一时间获取最新文章
转载文章受原作者版权保护。转载请注明原作者出处!